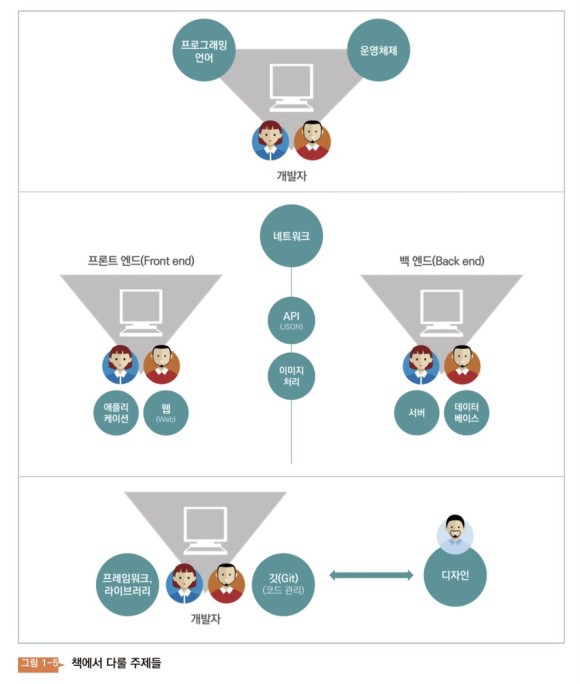
개발자는 앉아서 뭐 하지? 칠 줄 아는데… 어떻게 프로그래머가 저 단어와 기호를 줄줄 쓸 수 있을까요? 그 이유는 한 프로그램이 작업을 도와주기 때문이에요. 이 프로그램에는 앞서 말한 몇 글자만 입력하면 많이 쓰이는 문장을 추천해주기도 하고, 코드가 아닌 그림으로 작성할 수 있도록 하는 등 개발자의 작업을 도와주는 기능들이 들어가 있기도 합니다. 이런 프로그램을 IDE(통합개발환경, Integrated Development Environment)라고 부릅니다. 코딩에 필요한 여러가지 기능들을 포함하고 있으며, 해당 기능들을 통해서 코드를 쉽게 만들 수 있습니다.
- Android Studio: 안드로이드 어플리케이션 개발 용도 – Xcode: 어플리케이션 OS상의 어플리케이션 개발 용도 – 이클립스: C/C++ 개발, 자바 개발, 웹 개발 용도 – PyCharm: 파이썬 개발 용도
- 안드로이드 위로 돌아가는 어플리케이션을 만들기 위해서는 안드로이드 스튜디오라고 하는 IDE를 사용을 하겠습니다. 아이폰, 아이패드, 맥북 등 애플 기기의 앱 만들기는 X 코드라는 IDE를 사용합니다. 이렇게 IDE는 대부분 분야에 특화되어 있습니다.
- 컴퓨터의 구성 요소 → 우선 CPU가 있습니다. CPU는 컴퓨터가 ‘머리’ 역할을 해요. 다음은 ‘메모리’입니다. 마지막으로 HDD(하드디스크), SDD로 불리는 보조기억장치가 있습니다. 컴퓨터의 「창고」로서의 역할을 하고 있습니다. 전원이 꺼져도, 이 안의 데이터는 남아있습니다. 부품을 메인보드라고 하는 판에 끼워 넣습니다. 여기에 전원을 켜면 컴퓨터를 할 수 있어요.
- CPU는 컴퓨터 머리이고 보조 기억 장치인 HDD와 SSD는 컴퓨터 창고입니다. CPU는 따로 데이터를 저장하지 않기 때문에 데이터를 연산하거나 처리하기 위해서는 저장된 데이터를 CPU로 전송해야 합니다. 이때 CPU는 창고 역할을 하는 기억장치인 HDD, SSD로 신호를 보냅니다.
- 그런데 창고가 너무 커서 필요한 데이터를 찾기까지 시간이 오래 걸려요. 이처럼 보조기억장치는 CPU보다 속도가 매우 느리기 때문에 CPU와 보조기억장치가 함께 일을 하게 되면 CPU가 보조기억장치를 계속 기다려야 하기 때문에 속도가 하향평준화됩니다. 사람들은 CPU와 보조기억장치가 같이 작동하도록 하면 안 된다고 생각했어요.
- 그래서 ‘메모리’라고 하는 CPU로 프라이빗 워크스페이스를 만들었습니다. 현재 CPU는 보조기억장치에 필요한 데이터를 매번 요청할 필요가 없습니다. 작업에 필요한 큰 데이터 뭉치를 보조기억장치에서 메모리로 한 번 옮겨놓고 메모리 안에서만 작업하면 되기 때문입니다. 가끔 메모리 상에 큰 데이터 다발을 전달할 뿐이므로 시간이 크게 줄었습니다.
- 포토샵을 예로 들어보겠습니다.먼저 포토샵이 어디에 저장되어 있는지 생각해봅시다. Windows(OS) 기준의 「C드라이브-Program files-Adobe-Photoshop」의 포토 숍 실행에 필요한 파일이 있습니다. 보통 우리는 바탕화면에서 포토샵 아이콘을 ‘더블클릭’ 하거나 ‘시작’을 눌러 포토샵 아이콘을 클릭합니다. 이 과정은 “Program files-Adobe-Photoshop” 안에 있는 포토샵 실 감기 파일 바로 가기를 클릭합니다. 결국 보조기억장치에 저장된 프로그램을 실행하는 겁니다. 실행한다는 것은 cpu가 일한다는 뜻이에요. 하지만 그렇다고 해서 포토샵이 바로 실행되는 것은 아닙니다. 로드 화면이 나타나고 실행까지 시간이 좀 걸립니다. 이 과정에서 무슨 일이 일어나고 있을까요? 보조기억장치에서 실행에 필요한 데이터가 메모리에 업로드 됩니다. 이 프로세스가 완료되면 포토샵이 실행됩니다. 이제부터는 포토샵에서 사각형을 만들든 색을 바꾸든 CPU가 메모리 위에서 빠르게 작업을 수행하실 수 있습니다. 프로그램은 이렇게 돌아갑니다.
- ▲컴퓨터의 구성요소=사실 오늘 아침에도 CPU, 메모리, 보조기억장치와 함께 프로그램을 사용했다. 그런데 이 이야기가 왜 낯설까. 사실 이 모든 과정을 몰라도 프로그램을 사용하는 데 아무런 문제가 없다. 왜냐하면 어떤 소프트웨어가 이 모든 과정을 대행해 주기 때문이다. 그 어떤 소프트웨어가 바로 OS다. 대표적인 것으로 윈도 Mac OS iOS Android가 있다. 윈도와 맥 OS는 PC에서 많이 쓰이고 iOS와 안드로이드는 모바일에 특화되어 있다.
- 이 모든 운영체제(OS)는 한국 대신 하드웨어를 관리한다. 하드웨어 용량이 얼마나 되는지 확인할 수 있는 것도 운영체계가 보조기억장치(HDD, SSD)를 관리하고 있기 때문에 가능한 일이다. 프로그램을 인스톨/실행하는 것도 마찬가지다. 운영 체제가 하드웨어를 통제하고 CPU와 메모리 등을 관리해주기 때문에 우리는 클릭 몇 번만으로 편하게 파워포인트를 실행하고 카카오톡을 실행할 수 있다.

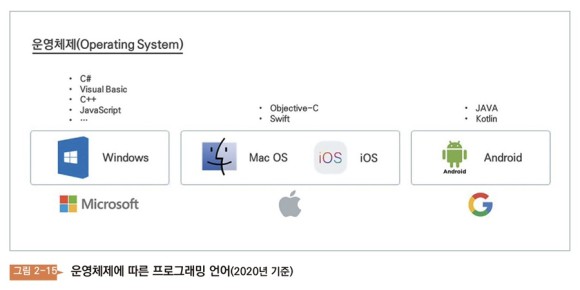
운영체제에 따른 프로그래밍 언어도 바뀐다. 따라서 각 운영체제 회사들은 개발자의 생활에도 큰 영향을 미치고 있다. 애플의 운영체제 위에 돌아가는 프로그램을 만들려면 Objective-C 또는 스위프트라는 언어를 써야 한다. 구글 운영체제 위로 돌아가는 프로그램을 만들려면 자바 또는 코틀린이라는 언어를 써야 한다.
우리가 자바의 최신 버전을 설치해야 하는 이유는 과거에는 운영체제의 종류가 훨씬 다양했기 때문에 개발자들이 배워야 할 프로그래밍 언어도 매우 많았다. 문제는 각기 다른 언어를 다 배웠더라도 프로그램 버그를 수정하거나 새로운 기능을 추가할 때 해야 할 일이 산더미처럼 늘어난다는 점. 10개의 운영체제가 있다면 같은 작업을 10회씩 해야 했다. 이 문제는 자바라는 프로그래밍 언어가 해결한다.
Java Virtual Machine이라는 소프트웨어를 만든 팀은 각각의 운영체제 위에 만들었다. JVM 위에서 자바 언어로 만든 프로그램을 가동할 수 있게 한 것이다. 사용자가 자신의 컴퓨터에 JVM만 설치해도 운영체제별로 여러 개의 프로그램을 만들 필요는 없고 자바로 만들기만 하면 된다. 즉, 「자바로」만 프로그램을 만들어도 모든 OS에서 사용할 수 있게 된 것이다.
자바 이외에도 다양한 언어가 이런 방식을 취하고 있다. 대표적인 것이 파이썬이다. 파이썬으로 프로그램을 만들면 윈도나 맥 OS 등의 OS 상에서 프로그램을 설치 및 실행할 수 있다. 물론 자바나 파이썬 같은 프로그램을 쓰는 단점도 있다. 속도가 느리다는 얘기다. 운영체제 위에 프로그램을 올려놓고 그 위에 다시 프로그램을 올려놓기 때문이다.
또 하나 알아야 할 사실은 모바일은 PC와 달리 IOS와 안드로이드가 시장을 양분하고 있다. 그 때문에, 종래보다 JVM와 같은 컨셉에 대한 요구가 적다. 또 모바일상에 특정 프로그램을 깔아놓고 그 위에 프로그램을 돌리는 방식을 쓰면 여러 문제가 발생한다. 우선 모바일은 기본적으로 크기가 PC보다 작기 때문에 그 안에 들어가는 부품 역시 PC보다 작다. 그 때문에, 용량이나 성능에 제한이 있다. 프로그램 위로 프로그램을 돌리면 너무 느리다.더욱이 이런 개념을 인정하면 애플과 구글이 가진 시장에 대한 영향력이 줄어들기 때문에 애플과 구글은 이런 상황을 원치 않는다. 따라서 모바일에서는 JVM와 같은 개념이 PC보다 상대적으로 발전하기 어렵다.
야! 내가 방 만들었어. 빨리 들어와! 어? 안 보이는데? 안 들어갈 거야! 그래? 그럼 네가 해봐. 내가 들어갈게! “그래, 잠깐만!” 만들었어!’방 없는데?’ 하아.(절망)
초등학교 컴퓨터 수업시간에는 이런 대화가 오갔다. 컴퓨터실에는 친구들과 게임을 할 수 있는 자리와 할 수 없는 자리가 나뉘어 있었기 때문이다. 이때 게임이 되는 자리, 안 되는 자리는 컴퓨터 연결이 어떻게 돼 있느냐에 따라 달라진다. 선으로 직접 연결된 컴퓨터는 서로 파일을 주고받거나 게임을 할 수 있었다. 그러나 연결되지 않는 두 개의 다른 컴퓨터는 함께 게임을 할 수 없었다. 중요한 사실을 배울 수 있다. 컴퓨터를 연결하면 할 수 있는 게 많구나!
컴퓨터가 연결되면 같이 게임을 할 수 있고 파일을 주고받을 수 있다. 덕분에 우리는 회사에서 엑셀 파일, PDF 파일 등 여러 가지 파일을 주고받으며 일할 수 있게 됐다. 컴퓨터가 연결된 작은 지역을 LAN(Local Area Network)이라고 한다. 학교 컴퓨터실 하나, 아파트 하나, 찻집 하나가 모두 랜이다. 랜을 연결하는 선을 랜선이라고 부른다. 또한 사람들은 도시의 다양한 LAN을 하나로 연결하여 MAN(Metropolitan Area Network)을 만들었다. 그리고 도시와 도시, 국가와 국가를 모두 연결하여 WAN(Wide Area Network)을 만들었다.
이 선을 연결하기 위해 당시 수많은 공사가 진행되었다. 정전도 많이 일어났다. 회사는 ADSL, VDSL, 광케이블 등 초고속인터넷망을 선전했다. 당시 컴퓨터실을 떠나 집에서 다른 친구들과 함께 게임을 할 수 있다는 것은 큰 충격이었다. 네트워크가 만들어낸 것이다. 이어 사람들은 이 신호를 무선으로 만들기 시작했다. 어느 순간 3G, 4G, 5G라는 말이 오갔다.
한강에서 카카오톡을 내려받아 실행하면 우선 앱스토어에 들어가 카카오톡을 검색한 뒤 다운로드 버튼을 누르면 인근 기지국으로 카카오톡 설치 파일을 보내라는 신호가 날아온다. 신호는 WAN에 따라 이동한다. 이때 항상 최종 목적지가 정해져 있다. 우편물을 생각하면 된다. 집 주소처럼 하나 정해진 컴퓨터 주소로 신호가 간다. 이곳에선 앱스토어에서 애플이 들고 있는 컴퓨터로 신호가 간다. 애플은 카카오톡 파일을 갖고 있다. 카카오가 앱스토어에 설치 파일을 올리고 있었기 때문이다. 현재 애플사의 컴퓨터는 카카오톡 설치 파일을 당신의 컴퓨터로 보내준다. 다운로드 중이라는 화면이 나타나고 잠시 후 카카오톡이 설치된다. 이후 앱을 클릭해 실행하면 운영체제에서 설명한 과정이 그대로 일어난다. 컴퓨터 보조기억장치(HDD, SSD)에 카카오톡 실행파일이 저장돼 여러분이 카카오톡 아이콘을 누르는 순간 실행에 필요한 부분이 메모리 위에 나타난다. 그리고 CPU가 이 데이터들을 처리하면서 카카오톡이 동작한다.
지금 설치된 카카오톡을 실행해 친구들이 보낸 이미지와 동영상을 내려받는다. 이미지나 동영상을 내려받을 때 일어나는 일들은 조금 전 앱스토어에서 카카오톡을 내려받은 과정과 같다. 동영상을 나에게 보내라는 신호를 가장 가까운 기지국에 보내면 카카오톡 프로그램이 지정해 놓은 주소에 따라 카카오톡 PC로 신호가 전송된다. 신호를 받은 컴퓨터에서는 이미지 파일, 동영상 파일 등을 보내준다. 그렇게 보낸 파일을 여러분의 스마트폰에서 볼 수 있는 것이다.
IP라는 말을 들어봤을 것이다. IP 주소는 문자 그대로 「주소」이다. 편지를 보낼 때 ‘서울 마포구 상암동 XX아파트 XX호’라는 주소가 필요하듯이 이미지 파일, 동영상 파일, 메시지 등을 보내려면 해당 컴퓨터가 위치한 주소가 필요하다. 그 주소를 IP 주소라고 한다. 인터넷에 접속하는 순간 여러분의 컴퓨터는 지금 위치에 맞는 IP 주소를 갖게 된다. IP 주소는 12자리 숫자가 온점(.)으로 구분된 모습을 보인다. IP 주소는 위치에 따라서, 컴퓨터에 의해서 고유하다. 즉, 집의 IP주소와 카페의 IP주소가 다르다는 얘기다. 이동하면 IP 주소는 계속 바뀐다.
당신은 계속 뭔가를 요구하고(클라이언트), 누군가는 계속 뭔가를 주는(서버) 카카오톡이 켜놓은 컴퓨터에 여러분처럼 파일을 주세요라는 신호를 많은 사람이 동시에 보낸다. 그럼 카톡 컴퓨터는 힘들어 죽겠다 컴퓨터는 개복치라서 스트레스 받으면 쉽게 죽는다. 엄청난 양의 신호가 컴퓨터에 깔리면 그 컴퓨터는 파일을 전송하는 데 보칙기억장치, 메모리, CPU를 사용한다. 파일을 보내기 위해서는 보조기억장치인 파일을 메모리에 올리고 CPU가 그 파일을 보내야 한다. 하지만 신호가 집중되면, 어느 순간 메모리의 스페이스를 모두 사용하게 되거나 CPU가 처리할 수 있는 한계를 넘어 버린다. 그러면 컴퓨터는 죽는다. 껐다 켜면 살 것 같아
이런 이유로 카카오톡은 여러 컴퓨터를 연합군으로 만들었다. 카카오톡은 이 컴퓨터 연합군을 24시간 365일 내내 기동시키고 있어 우리는 아침에도, 새벽에도, 저녁에도 카카오톡을 이용할 수 있다. 만약 이 컴퓨터들이 꺼지면 우리는 카카오톡을 사용할 수 없게 된다.
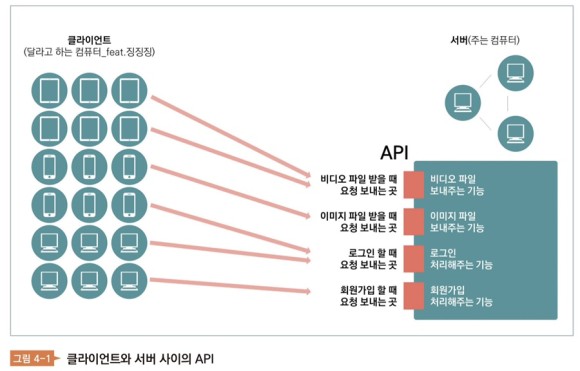
파일을 달라고 조르는 컴퓨터를 「클라이언트」, 파일을 주는 컴퓨터를 「서버」라고 한다. 개발자의 세계에서 클라이언트는 컴퓨터다. 서비스를 사용하는 사용자가 소유한 컴퓨터를 의미한다. 여러분의 스마트폰도 컴퓨터도 클라이언트이다. 한편, 고객의 입장에서 보면 클라이언트의 컴퓨터를 직접 볼 수 있고 만질 수도 있다. 고객 눈앞에 있는 이 클라이언트 컴퓨터를 다른 말로 프런트 엔드라고 표현한다. 한편, 서버는 고객의 눈에 들어오지 않는 곳에 있다. 고객에게 보이지 않는 곳, 거기서 서버를 다른 말로 「백엔드」라고 부른다.
도대체 우분투가 뭐야?이 질문에 답하려면 리눅스를 알아야 한다. 리눅스는 운영체제(OS)다.
“아 Linux는 윈도, 맥OS 같은 애들이구나” 아! 그럼 CPU, 메모리, 보조기억장치 등을 우리가 신경 쓰지 않아도 리눅스가 다 관리해 주는 거네.”아!” 그러면 윈도우 위에서 파워포인트 돌리듯이 리눅스 위에서 여러 가지 프로그램을 돌리겠네
리눅스라는 운영체제 위에서 ‘서버 프로그램’을 돌리는 ‘서버 프로그램’이 뭐지? 「서버」는 「클라이언트」의 요구에 응하는 컴퓨터이다. 카카오톡 컴퓨터나 애플 컴퓨터처럼 요청에 따라 파일을 보내준다. 이때 요청 종류는 다양해지는데 로그인, 회원가입, 상품리스트 요청, 결제 요청 등.
로그인 요청을 생각해 보자. 클라이언트에서 서버로 아래와 같이 요청한다.
“로그인 시켜줘”
그럼 어떤 정보가 필요할까? 「ID」와「패스워드」가 필요하다. 보통 이러한 정보는 로그인 요청을 할 때 함께 온다. 이제 정보를 받았으니 컴퓨터는 생각해야 한다. 어떻게 생각할까?
“이 아이디가 존재하는 건가?” 존재한다면 비밀번호는 이건가?’
컴퓨터가 생각한다는 것은 코딩된 프로그램이 동작하는 것을 의미한다. 프로그래밍 언어로 컴퓨터에 일을 시킨 것이다. 하드웨어를 직접 통제하지 않으려면 운영체제 위에서 프로그램을 돌려야 한다. 즉 리눅스 위에 이렇게 생각하는 프로그램을 24시간 365일 치환하는 것이다. 그럼, 해당 프로그램이 코딩된 채로 생각하고 회답해 준다.-
그렇다면 왜 서버 프로그램을 Linux 위에서 돌리는 것인가. Windows OS, Mac OS, iOS, Android OS의 경우 굳이 리눅스를 사용하는 이유는 무엇인가? 그 이유는 Linux가 기본적으로 무료이기 때문이다. Linux의 무료 배포로 국민들은 이 제도를 발전시켰다. 그렇게 다양한 버전의 리.
운영체제에 따른 프로그래밍 언어도 바뀐다. 따라서 각 운영체제 회사들은 개발자의 생활에도 큰 영향을 미치고 있다. 애플의 운영체제 위에 돌아가는 프로그램을 만들려면 Objective-C 또는 스위프트라는 언어를 써야 한다. 구글 운영체제 위로 돌아가는 프로그램을 만들려면 자바 또는 코틀린이라는 언어를 써야 한다.
우리가 자바의 최신 버전을 설치해야 하는 이유는 과거에는 운영체제의 종류가 훨씬 다양했기 때문에 개발자들이 배워야 할 프로그래밍 언어도 매우 많았다. 문제는 각기 다른 언어를 다 배웠더라도 프로그램 버그를 수정하거나 새로운 기능을 추가할 때 해야 할 일이 산더미처럼 늘어난다는 점. 10개의 운영체제가 있다면 같은 작업을 10회씩 해야 했다. 이 문제는 자바라는 프로그래밍 언어가 해결한다.
Java Virtual Machine이라는 소프트웨어를 만든 팀은 각각의 운영체제 위에 만들었다. JVM 위에서 자바 언어로 만든 프로그램을 가동할 수 있게 한 것이다. 사용자가 자신의 컴퓨터에 JVM만 설치해도 운영체제별로 여러 개의 프로그램을 만들 필요는 없고 자바로 만들기만 하면 된다. 즉, 「자바로」만 프로그램을 만들어도 모든 OS에서 사용할 수 있게 된 것이다.
자바 이외에도 다양한 언어가 이런 방식을 취하고 있다. 대표적인 것이 파이썬이다. 파이썬으로 프로그램을 만들면 윈도나 맥 OS 등의 OS 상에서 프로그램을 설치 및 실행할 수 있다. 물론 자바나 파이썬 같은 프로그램을 쓰는 단점도 있다. 속도가 느리다는 얘기다. 운영체제 위에 프로그램을 올려놓고 그 위에 다시 프로그램을 올려놓기 때문이다.
또 하나 알아야 할 사실은 모바일은 PC와 달리 IOS와 안드로이드가 시장을 양분하고 있다. 그 때문에, 종래보다 JVM와 같은 컨셉에 대한 요구가 적다. 또 모바일상에 특정 프로그램을 깔아놓고 그 위에 프로그램을 돌리는 방식을 쓰면 여러 문제가 발생한다. 우선 모바일은 기본적으로 크기가 PC보다 작기 때문에 그 안에 들어가는 부품 역시 PC보다 작다. 그 때문에, 용량이나 성능에 제한이 있다. 프로그램 위로 프로그램을 돌리면 너무 느리다.더욱이 이런 개념을 인정하면 애플과 구글이 가진 시장에 대한 영향력이 줄어들기 때문에 애플과 구글은 이런 상황을 원치 않는다. 따라서 모바일에서는 JVM와 같은 개념이 PC보다 상대적으로 발전하기 어렵다.
야! 내가 방 만들었어. 빨리 들어와! 어? 안 보이는데? 안 들어갈 거야! 그래? 그럼 네가 해봐. 내가 들어갈게! “그래, 잠깐만!” 만들었어!’방 없는데?’ 하아.(절망)
초등학교 컴퓨터 수업시간에는 이런 대화가 오갔다. 컴퓨터실에는 친구들과 게임을 할 수 있는 자리와 할 수 없는 자리가 나뉘어 있었기 때문이다. 이때 게임이 되는 자리, 안 되는 자리는 컴퓨터 연결이 어떻게 돼 있느냐에 따라 달라진다. 선으로 직접 연결된 컴퓨터는 서로 파일을 주고받거나 게임을 할 수 있었다. 그러나 연결되지 않는 두 개의 다른 컴퓨터는 함께 게임을 할 수 없었다. 중요한 사실을 배울 수 있다. 컴퓨터를 연결하면 할 수 있는 게 많구나!
컴퓨터가 연결되면 같이 게임을 할 수 있고 파일을 주고받을 수 있다. 덕분에 우리는 회사에서 엑셀 파일, PDF 파일 등 여러 가지 파일을 주고받으며 일할 수 있게 됐다. 컴퓨터가 연결된 작은 지역을 LAN(Local Area Network)이라고 한다. 학교 컴퓨터실 하나, 아파트 하나, 찻집 하나가 모두 랜이다. 랜을 연결하는 선을 랜선이라고 부른다. 또한 사람들은 도시의 다양한 LAN을 하나로 연결하여 MAN(Metropolitan Area Network)을 만들었다. 그리고 도시와 도시, 국가와 국가를 모두 연결하여 WAN(Wide Area Network)을 만들었다.
이 선을 연결하기 위해 당시 수많은 공사가 진행되었다. 정전도 많이 일어났다. 회사는 ADSL, VDSL, 광케이블 등 초고속인터넷망을 선전했다. 당시 컴퓨터실을 떠나 집에서 다른 친구들과 함께 게임을 할 수 있다는 것은 큰 충격이었다. 네트워크가 만들어낸 것이다. 이어 사람들은 이 신호를 무선으로 만들기 시작했다. 어느 순간 3G, 4G, 5G라는 말이 오갔다.
한강에서 카카오톡을 내려받아 실행하면 우선 앱스토어에 들어가 카카오톡을 검색한 뒤 다운로드 버튼을 누르면 인근 기지국으로 카카오톡 설치 파일을 보내라는 신호가 날아온다. 신호는 WAN에 따라 이동한다. 이때 항상 최종 목적지가 정해져 있다. 우편물을 생각하면 된다. 집 주소처럼 하나 정해진 컴퓨터 주소로 신호가 간다. 이곳에선 앱스토어에서 애플이 들고 있는 컴퓨터로 신호가 간다. 애플은 카카오톡 파일을 갖고 있다. 카카오가 앱스토어에 설치 파일을 올리고 있었기 때문이다. 현재 애플사의 컴퓨터는 카카오톡 설치 파일을 당신의 컴퓨터로 보내준다. 다운로드 중이라는 화면이 나타나고 잠시 후 카카오톡이 설치된다. 이후 앱을 클릭해 실행하면 운영체제에서 설명한 과정이 그대로 일어난다. 컴퓨터 보조기억장치(HDD, SSD)에 카카오톡 실행파일이 저장돼 여러분이 카카오톡 아이콘을 누르는 순간 실행에 필요한 부분이 메모리 위에 나타난다. 그리고 CPU가 이 데이터들을 처리하면서 카카오톡이 동작한다.
지금 설치된 카카오톡을 실행해 친구들이 보낸 이미지와 동영상을 내려받는다. 이미지나 동영상을 내려받을 때 일어나는 일들은 조금 전 앱스토어에서 카카오톡을 내려받은 과정과 같다. 동영상을 나에게 보내라는 신호를 가장 가까운 기지국에 보내면 카카오톡 프로그램이 지정해 놓은 주소에 따라 카카오톡 PC로 신호가 전송된다. 신호를 받은 컴퓨터에서는 이미지 파일, 동영상 파일 등을 보내준다. 그렇게 보낸 파일을 여러분의 스마트폰에서 볼 수 있는 것이다.
IP라는 말을 들어봤을 것이다. IP 주소는 문자 그대로 「주소」이다. 편지를 보낼 때 ‘서울 마포구 상암동 XX아파트 XX호’라는 주소가 필요하듯이 이미지 파일, 동영상 파일, 메시지 등을 보내려면 해당 컴퓨터가 위치한 주소가 필요하다. 그 주소를 IP 주소라고 한다. 인터넷에 접속하는 순간 여러분의 컴퓨터는 지금 위치에 맞는 IP 주소를 갖게 된다. IP 주소는 12자리 숫자가 온점(.)으로 구분된 모습을 보인다. IP 주소는 위치에 따라서, 컴퓨터에 의해서 고유하다. 즉, 집의 IP주소와 카페의 IP주소가 다르다는 얘기다. 이동하면 IP 주소는 계속 바뀐다.
당신은 계속 뭔가를 요구하고(클라이언트), 누군가는 계속 뭔가를 주는(서버) 카카오톡이 켜놓은 컴퓨터에 여러분처럼 파일을 주세요라는 신호를 많은 사람이 동시에 보낸다. 그럼 카톡 컴퓨터는 힘들어 죽겠다 컴퓨터는 개복치라서 스트레스 받으면 쉽게 죽는다. 엄청난 양의 신호가 컴퓨터에 깔리면 그 컴퓨터는 파일을 전송하는 데 보칙기억장치, 메모리, CPU를 사용한다. 파일을 보내기 위해서는 보조기억장치인 파일을 메모리에 올리고 CPU가 그 파일을 보내야 한다. 하지만 신호가 집중되면, 어느 순간 메모리의 스페이스를 모두 사용하게 되거나 CPU가 처리할 수 있는 한계를 넘어 버린다. 그러면 컴퓨터는 죽는다. 껐다 켜면 살 것 같아
이런 이유로 카카오톡은 여러 컴퓨터를 연합군으로 만들었다. 카카오톡은 이 컴퓨터 연합군을 24시간 365일 내내 기동시키고 있어 우리는 아침에도, 새벽에도, 저녁에도 카카오톡을 이용할 수 있다. 만약 이 컴퓨터들이 꺼지면 우리는 카카오톡을 사용할 수 없게 된다.
파일을 달라고 조르는 컴퓨터를 「클라이언트」, 파일을 주는 컴퓨터를 「서버」라고 한다. 개발자의 세계에서 클라이언트는 컴퓨터다. 서비스를 사용하는 사용자가 소유한 컴퓨터를 의미한다. 여러분의 스마트폰도 컴퓨터도 클라이언트이다. 한편, 고객의 입장에서 보면 클라이언트의 컴퓨터를 직접 볼 수 있고 만질 수도 있다. 고객 눈앞에 있는 이 클라이언트 컴퓨터를 다른 말로 프런트 엔드라고 표현한다. 한편, 서버는 고객의 눈에 들어오지 않는 곳에 있다. 고객에게 보이지 않는 곳, 거기서 서버를 다른 말로 「백엔드」라고 부른다.
도대체 우분투가 뭐야?이 질문에 답하려면 리눅스를 알아야 한다. 리눅스는 운영체제(OS)다.
“아 Linux는 윈도, 맥OS 같은 애들이구나” 아! 그럼 CPU, 메모리, 보조기억장치 등을 우리가 신경 쓰지 않아도 리눅스가 다 관리해 주는 거네.”아!” 그러면 윈도우 위에서 파워포인트 돌리듯이 리눅스 위에서 여러 가지 프로그램을 돌리겠네
리눅스라는 운영체제 위에서 ‘서버 프로그램’을 돌리는 ‘서버 프로그램’이 뭐지? 「서버」는 「클라이언트」의 요구에 응하는 컴퓨터이다. 카카오톡 컴퓨터나 애플 컴퓨터처럼 요청에 따라 파일을 보내준다. 이때 요청 종류는 다양해지는데 로그인, 회원가입, 상품리스트 요청, 결제 요청 등.
로그인 요청을 생각해 보자. 클라이언트에서 서버로 아래와 같이 요청한다.
“로그인 시켜줘”
그럼 어떤 정보가 필요할까? 「ID」와「패스워드」가 필요하다. 보통 이러한 정보는 로그인 요청을 할 때 함께 온다. 이제 정보를 받았으니 컴퓨터는 생각해야 한다. 어떻게 생각할까?
“이 아이디가 존재하는 건가?” 존재한다면 비밀번호는 이건가?’
컴퓨터가 생각한다는 것은 코딩된 프로그램이 동작하는 것을 의미한다. 프로그래밍 언어로 컴퓨터에 일을 시킨 것이다. 하드웨어를 직접 통제하지 않으려면 운영체제 위에서 프로그램을 돌려야 한다. 즉 리눅스 위에 이렇게 생각하는 프로그램을 24시간 365일 치환하는 것이다. 그럼, 해당 프로그램이 코딩된 채로 생각하고 회답해 준다.-
그렇다면 왜 서버 프로그램을 Linux 위에서 돌리는 것인가. Windows OS, Mac OS, iOS, Android OS의 경우 굳이 리눅스를 사용하는 이유는 무엇인가? 그 이유는 Linux가 기본적으로 무료이기 때문이다. Linux의 무료 배포로 국민들은 이 제도를 발전시켰다. 그렇게 다양한 버전의 리.
‘정확한 장소’에 해당하는 어드레스는 ‘서버 주소/A’ 형태로 정의되어 있다. 여기서 ‘서버 주소’는 서버 컴퓨터가 있는 곳의 주소이다. 네트워크에서 언급한 IP 주소이다. 그 어드레스 뒤에 어떤 문자를 사용하느냐에 따라 다른 기능을 수행하도록 정의하는 것이다. 예를 들어, 「서버 주소/A」라고 하는 신호를 보내면, 서버가 「로그인 기능」을 실행하고 응답한다. 혹은 ‘서버 주소/B’라는 신호를 보내면 서버가 ‘회원가입 기능’을 실행하여 응답한다. 잘 되었는지, 혹시 문제가 있으면 무슨 문제가 있는지 등을 알려준다. 이러한 기능은 서버 개발자가 만들고, 그 결과물이 서버 프로그램이다. 서버 주소 정의도 서버 개발자의 주도하에서 행해진다. 그리고 클라이언트 프로그램은 정해진 주소로 요청을 보낸다. 즉, API는 서버 개발자가 개발하고 클라이언트 개발자는 그 API를 사용한다.
API를 만들 때는 데이터를 주고받는 기능도 함께 도입한다. 로그인 요청 시 ID와 비밀번호 데이터가 필요하다. 비디오 파일이나 이미지 파일에 대한 답변을 받을 때도 데이터가 함께 와야 한다. 이처럼 API를 통해 요청과 응답을 주고받을 때는 데이터도 함께 담는다.
그러면 API를 클라이언트와 서버의 관점에서 좀 더 자세하게 살펴보자.
우선은 클라이언트의 관점에서 살펴보자.클라이언트 소프트웨어는 서버에 요청을 보낸다. 타임라인 사진 올리기 요청으로 볼 때 이 요청을 크게 네 가지 요소로 나눌 수 있다. CRUD라 불리는 이 4가지 요청은 데이터를 취급할 때의 기준이 되는 요청으로, 프로그래머에게 매우 중요하다.
데이터를 다룰 때 큰 틀에서 보면 대부분의 요청은 이 4가지 요청(CRUD)에 속한다.C:CREATE -> 타임라인에 사진 올리기 요청 R:READ -> 타임라인에 사진 불러오기 요청 U:UPDATE -> 바꾸기 요청 D:DELETE -> 지우기 요청
개발자들은 데이터를 볼 때 항상 CRUD 관점에서 생각한다. 하지만 초보 기획자들은 쉽지 않다. 그래서 실수를 해 예를 들면, 데이터는 볼 수 있는데 만드는 기획이 없는 것도 있다. 혹은 보거나 만들거나 하는 기획은 있지만, 수정하거나 삭제하거나 하는 기획이 없는 것도 있다. 이 같은 실수를 방지하기 위해서는 데이터를 CRUD 관점에서 바라봐야 한다. 만약 CRUD 중 특정 기능이 없는 기획이라면 그 기획 의도가 명확해야 하고, 이유도 설명할 수 있어야 한다.
RESTful API 타임라인의 CRUD 요청은 각각 주소를 갖는다.예를 들어 CREATE 리퀘스트는 “서버 컴퓨터의 어드레스/time line create”로 할 수 있다. READ, UPDATE, DELTE도 각각의 주소를 갖는다. 그러면 서버의 기능을 원하는 클라이언트는 해당 주소로 요청을 보내면 된다. 이렇게 CRUD별로 주소가 생긴다. 그런데 이렇게 주소를 구성하면 문제가 있다. 주소가 너무 많아져 관리가 어렵다는 것이다. 프로그래밍은 사람이 하는 일이기 때문에 몇몇 주소는 기능이 중복될 수 있고 CRUD가 체계적으로 분리되지 않을 수 있다. 그러면 API가 몇 가지 문제를 일으켜 버그가 생긴다. 따라서 사람들은 API를 보다 체계적으로 관리하고 싶어 하며, 그 영향으로 보다 체계적인 API라는 사회운동이 만들어지게 된다. 그러한 API를 REST(Representational State Transfer)한 API, 즉 RESTful API라 부른다.
RESTful API가 어떤 체계인가가 중요하다. RESTful API에서는 CRUD를 하나의 어드레스로서 관리하려면 이전보다 어드레스 수가 줄어든다. 그리고 요청을 보낼 때 다음과 같이 어떤 요청을 보냈는지 파악할 수 있는 ‘스티커(= 메서드)’를 붙여 함께 발송한다.
이 스티커 5개는 자주 쓰이니까 꼭 알아두자. – CREATE(생성해) : POST-READ(불러와) : GET-UPDATE(바꿔줘) : PUT(전체) / PATCH(일부) – DELETE(지워줘) : DELETE
*RESTful API는 모든 회사에서 통용되는 절대적인 규칙이 아닌 일종의 운동이며, 상황에 따라 다양한 방식으로 변형되어 사용되고 있다.
- 현업에서는 ‘스티커’ 대신 ‘메서드’라는 용어를 사용한다. 메서드는 ‘방법’이라는 의미의 영어 단어인데, 개발자의 세계에서는 수학의 ‘함수’와 같은 의미로 쓰인다. x 라는 입력값에 따라 y 라는 결과가 나오는 것이 함수이듯이, 요청을 보내면 결과가 나오는 API의 모습이 함수와 같기 때문에 ‘메서드’라는 용어를 사용한다. 함수에서는 x를 ‘변수’, ‘파라미터’라 사용한다. API에서도 마찬가지다. 예를 들어 로그인 요구에 있어서 필요한 ID와 패스워드를 ‘로그인 요구에 필요한 요구 변수’ 혹은 ‘파라미터’로 표현한다.
- 이제 서버의 관점에서 API를 생각해 보자.클래로부터 요청을 보내면, 서버는 다음과 같이 생각한다.
- ‘신청한 사용자가 등록한 사용자냐?’ 이거 비밀번호 틀렸어! 확인해 보라고 해줘 “친구 중에 A를 찾아달라고?” A 없는데? 없다고 말해주자” 친구 목록을 보내달라고? 친구가 없어비밀번호를 까먹었다고? 재설정이 필요한지 물어보자.
- 컴퓨터가 생각한다는 것은 개발자가 코딩했다는 것을 의미한다. 여기서 이러한 코딩은 서버 개발자가 실시한다. 그리고 컴퓨터는 코딩된 대로 생각하고 답을 보낸다. 응답에는 2가지 경우가 있다. 하나는 ‘잘됐다’고, 다른 하나는 ‘잘못했다’다. 개발자들은 잘됐다나 못됐다에도 시스템이 필요하다고 생각했다. 그래서 ‘좋았어’는 200번대 코드(201, 202)… 등)로 표현하기로 했다.
- 잘 되지 않았다는 두 가지 사례가 있다. 클래의 요청 때문에 잘 되지 않았던 경우와 서버 내부에서 잘 되지 않았던 경우가 있다. 이 두 가지 경우를 다르게 표현하면 문제가 생겼을 때 원인을 찾기 쉽다. 그래서 쿠라의 요청으로 문제가 생겼을 경우 400번대의 코드(401, 404…)로 표현하기로 했다. 반면 서버에 문제가 있을 경우 500번대 코드(500, 501…)로 표현하기로 했다. 404 라는 에러 코드는 보통 정의되지 않은 요청을 보낼 때 표시된다. 즉, 서버는 순조롭게 가동되고 있는데, 요청이 이상하다는 것이 된다.
- 정리하면 API는 소프트웨어가 다른 소프트웨어의 기능을 쓰기 위해 중간에 필요한 체계이다. 간단히 말하면, 기능을 사용하기 위해서 주소로 리퀘스트를 보내면 회답해 주는 소프트웨어끼리의 구조로 이해하면 된다.
SDK(Software Development Kit) – API를 제공하는 다른 소프트웨어 API의 개념을 좀 더 확장해 보자. 우리는 지금까지 크라와 서버의 두 시스템을 보아왔다. 하지만 다를 수 있다. 하나의 컴퓨터에 복수의 소프트웨어가 설치되어 있는 경우이다.
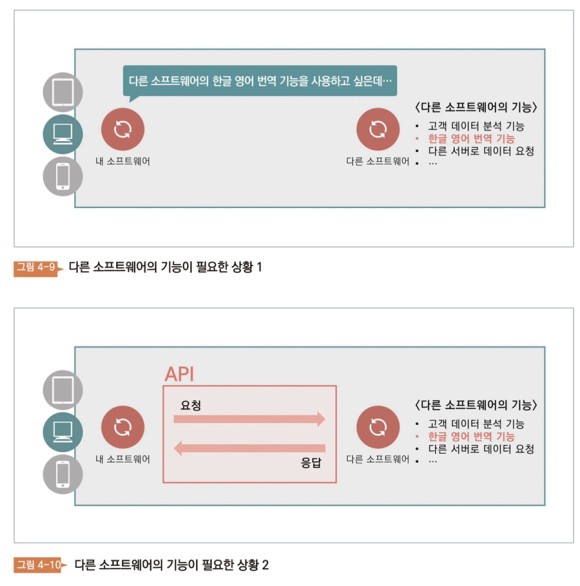
예를 들어보자. 내 컴퓨터에서 ‘XX 소프트웨어’를 개발 중이라고 하자. 그런데 문제가 생겼다. 「XX 소프트웨어」의 1 파트에 「한영역 기능」이 필요한 상황이 생긴 것이다. 이때 한 소프트웨어가 한영역 기능을 가지고 있어서 우리는 그 소프트웨어의 한영역 기능을 사용하고 싶다. 다른 시스템의 기능을 사용하기 위해서는 API가 필요하다.
‘정확한 장소’에 해당하는 어드레스는 ‘서버 주소/A’ 형태로 정의되어 있다. 여기서 ‘서버 주소’는 서버 컴퓨터가 있는 곳의 주소이다. 네트워크에서 언급한 IP 주소이다. 그 어드레스 뒤에 어떤 문자를 사용하느냐에 따라 다른 기능을 수행하도록 정의하는 것이다. 예를 들어, 「서버 주소/A」라고 하는 신호를 보내면, 서버가 「로그인 기능」을 실행하고 응답한다. 혹은 ‘서버 주소/B’라는 신호를 보내면 서버가 ‘회원가입 기능’을 실행하여 응답한다. 잘 되었는지, 혹시 문제가 있으면 무슨 문제가 있는지 등을 알려준다. 이러한 기능은 서버 개발자가 만들고, 그 결과물이 서버 프로그램이다. 서버 주소 정의도 서버 개발자의 주도하에서 행해진다. 그리고 클라이언트 프로그램은 정해진 주소로 요청을 보낸다. 즉, API는 서버 개발자가 개발하고 클라이언트 개발자는 그 API를 사용한다.
API를 만들 때는 데이터를 주고받는 기능도 함께 도입한다. 로그인 요청 시 ID와 비밀번호 데이터가 필요하다. 비디오 파일이나 이미지 파일에 대한 답변을 받을 때도 데이터가 함께 와야 한다. 이처럼 API를 통해 요청과 응답을 주고받을 때는 데이터도 함께 담는다.
그러면 API를 클라이언트와 서버의 관점에서 좀 더 자세하게 살펴보자.
우선은 클라이언트의 관점에서 살펴보자.클라이언트 소프트웨어는 서버에 요청을 보낸다. 타임라인 사진 올리기 요청으로 볼 때 이 요청을 크게 네 가지 요소로 나눌 수 있다. CRUD라 불리는 이 4가지 요청은 데이터를 취급할 때의 기준이 되는 요청으로, 프로그래머에게 매우 중요하다.
데이터를 다룰 때 큰 틀에서 보면 대부분의 요청은 이 4가지 요청(CRUD)에 속한다.C:CREATE -> 타임라인에 사진 올리기 요청 R:READ -> 타임라인에 사진 불러오기 요청 U:UPDATE -> 바꾸기 요청 D:DELETE -> 지우기 요청
개발자들은 데이터를 볼 때 항상 CRUD 관점에서 생각한다. 하지만 초보 기획자들은 쉽지 않다. 그래서 실수를 해 예를 들면, 데이터는 볼 수 있는데 만드는 기획이 없는 것도 있다. 혹은 보거나 만들거나 하는 기획은 있지만, 수정하거나 삭제하거나 하는 기획이 없는 것도 있다. 이 같은 실수를 방지하기 위해서는 데이터를 CRUD 관점에서 바라봐야 한다. 만약 CRUD 중 특정 기능이 없는 기획이라면 그 기획 의도가 명확해야 하고, 이유도 설명할 수 있어야 한다.
RESTful API 타임라인의 CRUD 요청은 각각 주소를 갖는다.예를 들어 CREATE 리퀘스트는 “서버 컴퓨터의 어드레스/time line create”로 할 수 있다. READ, UPDATE, DELTE도 각각의 주소를 갖는다. 그러면 서버의 기능을 원하는 클라이언트는 해당 주소로 요청을 보내면 된다. 이렇게 CRUD별로 주소가 생긴다. 그런데 이렇게 주소를 구성하면 문제가 있다. 주소가 너무 많아져 관리가 어렵다는 것이다. 프로그래밍은 사람이 하는 일이기 때문에 몇몇 주소는 기능이 중복될 수 있고 CRUD가 체계적으로 분리되지 않을 수 있다. 그러면 API가 몇 가지 문제를 일으켜 버그가 생긴다. 따라서 사람들은 API를 보다 체계적으로 관리하고 싶어 하며, 그 영향으로 보다 체계적인 API라는 사회운동이 만들어지게 된다. 그러한 API를 REST(Representational State Transfer)한 API, 즉 RESTful API라 부른다.
RESTful API가 어떤 체계인가가 중요하다. RESTful API에서는 CRUD를 하나의 어드레스로서 관리하려면 이전보다 어드레스 수가 줄어든다. 그리고 요청을 보낼 때 다음과 같이 어떤 요청을 보냈는지 파악할 수 있는 ‘스티커(= 메서드)’를 붙여 함께 발송한다.
이 스티커 5개는 자주 쓰이니까 꼭 알아두자. – CREATE(생성해) : POST-READ(불러와) : GET-UPDATE(바꿔줘) : PUT(전체) / PATCH(일부) – DELETE(지워줘) : DELETE
*RESTful API는 모든 회사에서 통용되는 절대적인 규칙이 아닌 일종의 운동이며, 상황에 따라 다양한 방식으로 변형되어 사용되고 있다.
- 현업에서는 ‘스티커’ 대신 ‘메서드’라는 용어를 사용한다. 메서드는 ‘방법’이라는 의미의 영어 단어인데, 개발자의 세계에서는 수학의 ‘함수’와 같은 의미로 쓰인다. x 라는 입력값에 따라 y 라는 결과가 나오는 것이 함수이듯이, 요청을 보내면 결과가 나오는 API의 모습이 함수와 같기 때문에 ‘메서드’라는 용어를 사용한다. 함수에서는 x를 ‘변수’, ‘파라미터’라 사용한다. API에서도 마찬가지다. 예를 들어 로그인 요구에 있어서 필요한 ID와 패스워드를 ‘로그인 요구에 필요한 요구 변수’ 혹은 ‘파라미터’로 표현한다.
- 이제 서버의 관점에서 API를 생각해 보자.클래로부터 요청을 보내면, 서버는 다음과 같이 생각한다.
- ‘신청한 사용자가 등록한 사용자냐?’ 이거 비밀번호 틀렸어! 확인해 보라고 해줘 “친구 중에 A를 찾아달라고?” A 없는데? 없다고 말해주자” 친구 목록을 보내달라고? 친구가 없어비밀번호를 까먹었다고? 재설정이 필요한지 물어보자.
- 컴퓨터가 생각한다는 것은 개발자가 코딩했다는 것을 의미한다. 여기서 이러한 코딩은 서버 개발자가 실시한다. 그리고 컴퓨터는 코딩된 대로 생각하고 답을 보낸다. 응답에는 2가지 경우가 있다. 하나는 ‘잘됐다’고, 다른 하나는 ‘잘못했다’다. 개발자들은 잘됐다나 못됐다에도 시스템이 필요하다고 생각했다. 그래서 ‘좋았어’는 200번대 코드(201, 202)… 등)로 표현하기로 했다.
- 잘 되지 않았다는 두 가지 사례가 있다. 클래의 요청 때문에 잘 되지 않았던 경우와 서버 내부에서 잘 되지 않았던 경우가 있다. 이 두 가지 경우를 다르게 표현하면 문제가 생겼을 때 원인을 찾기 쉽다. 그래서 쿠라의 요청으로 문제가 생겼을 경우 400번대의 코드(401, 404…)로 표현하기로 했다. 반면 서버에 문제가 있을 경우 500번대 코드(500, 501…)로 표현하기로 했다. 404 라는 에러 코드는 보통 정의되지 않은 요청을 보낼 때 표시된다. 즉, 서버는 순조롭게 가동되고 있는데, 요청이 이상하다는 것이 된다.
- 정리하면 API는 소프트웨어가 다른 소프트웨어의 기능을 쓰기 위해 중간에 필요한 체계이다. 간단히 말하면, 기능을 사용하기 위해서 주소로 리퀘스트를 보내면 회답해 주는 소프트웨어끼리의 구조로 이해하면 된다.
SDK(Software Development Kit) – API를 제공하는 다른 소프트웨어 API의 개념을 좀 더 확장해 보자. 우리는 지금까지 크라와 서버의 두 시스템을 보아왔다. 하지만 다를 수 있다. 하나의 컴퓨터에 복수의 소프트웨어가 설치되어 있는 경우이다.
예를 들어보자. 내 컴퓨터에서 ‘XX 소프트웨어’를 개발 중이라고 하자. 그런데 문제가 생겼다. 「XX 소프트웨어」의 1 파트에 「한영역 기능」이 필요한 상황이 생긴 것이다. 이때 한 소프트웨어가 한영역 기능을 가지고 있어서 우리는 그 소프트웨어의 한영역 기능을 사용하고 싶다. 다른 시스템의 기능을 사용하기 위해서는 API가 필요하다.
XX 소프트웨어는 API를 사용하여 정해진 방법대로 다른 소프트웨어에 요청을 보낸다. 「다른 소프트웨어」는, 요청대로 작업을 실시해, 답변을 준다. 물론 API는 답변을 보내는 쪽이 만들고 요청을 보내는 쪽은 활용할 뿐이다. 즉, 해당 API를 미리 만들어 놓아야만 쓸 수 있는 것이다.
이때 새로운 용어가 하나 등장한다. 바로 SDK다. API를 제공하는 ‘다른 소프트웨어’를 SDK라 부른다. SDK는 소프트웨어를 개발하기 위한 툴이다. 즉, 「XX 소프트웨어」를 개발할 때에 도움이 되는 「다른 소프트웨어」이다. 보통 다른 회사와 협업할 때 SDK라는 말을 듣게 된다.

구체적인 예를 들어보자. 구글 지도는 구글에서 만든 소프트웨어다. 이때 다른 회사도 구글이 제공하는 지도 SDK를 설치하면 자신의 소프트웨어에 구글 지도 기능을 넣을 수 있다. 이 SDK가 제공하는 API를 통해 구글 지도에 요청을 보낼 수 있다.
JSON-요청서와 응답을 주고받을 때 형식 API로, 우리는 클라가 서버로 보내는 리퀘스트(request)와 서버가 클라에게 보내는 응답(response)에 대해 공부했다. 그리고 요청과 응답을 할 때는 데이터를 넣을 수 있기 때문에 데이터를 넣을 수 있는 ‘기능’을 함께 개발해야 한다는 것도 배웠다. 그런데 데이터를 가져올 수 있는 「기능」에는 여러가지 형식이 있다.
먼저 형식이 무엇인지 보자. 클라가 서버에 ‘ID, 요청 날짜, 다른 정보’를 보낸다고 가정해 보자. 정보를 광범한 형식으로 전송할 수 있다.
형식 1 [ID, 요청 날짜, 다른 정보//wychoi0709, 20181022, 어떻게든]
형식 2 {ID: wychoi0709, 요청일 : 20181022, 다른 정보 : 어떻게든}
형식 3[아이디,wychoi0709),(요청날짜,20181022),(다른정보,어떻게든)
…이처럼 무한한 형식을 만들어 낼 수 있다는 것이 문제다. 요청을 보낼 때, 혹은 답변을 받을 때 요청 또는 답변별로 형식이 다를 수 있다. 그러면 그 형식을 처리하기 위한 코드를 또 써야 한다. 80개의 요청이 모두 다른 경우에는 80가지 형식에 맞는 코드를 기입해야 한다. 매우 비효율적이다. 그래서 개발자들은 생각했다. 그 유명한 형식을 다 같이 쓰면 안 되는 건가?’
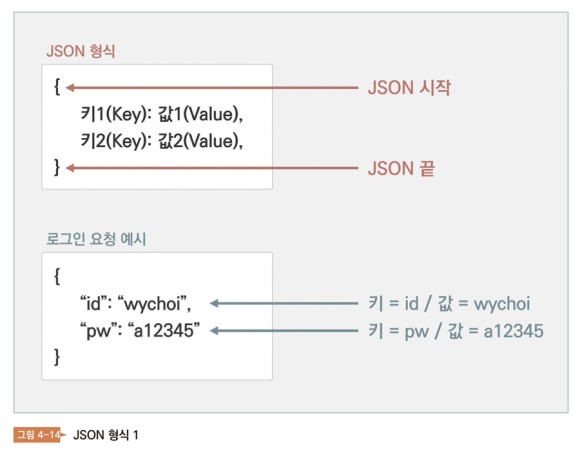
과거에는 XML 이라는 형식이 널리 사용되었으며, 지금도 자주 사용되지만 현재 가장 유명한 형식은 JSON이다. 그러면 JSON이 어떤 모습인지 보자
JSON은 중괄호 {}로 시작한다. 클리고키(Key)와 값(value)으로 이루어져 있다. 그 키와 값은 콜론(:)으로 구분한다.
만약 쇼핑몰의 메인 페이지에서 상품 정보를 읽는다고 가정해 보자. 이때상품정보를한마디만읽지말자. 다양한 상품 정보를 읽어야 한다. 이때는 배열(array)이라는 형식이 필요하다. JSON 에서는 대괄호[ ] 로 배열을 표시한다. 즉, ‘상품1’, ‘상품2’, ‘상품3’이라고 기재한다.
이 JSON을 활용해 개발자들은 이렇게 말한다.그 정보는 JSON으로 전송되었습니다.로그인 API 응답보낼때 JSON안에 같이 넣어서 보냅니다.그건 JSON에 들어있어요.
대화를 보면 JSON이 꼭 데이터를 주고받는 주머니 같다. 개발자가 이렇게 말하는 이유는 JSON이라는 파일 때문이다. 그 파일안에 JSON형식으로 데이터가 들어간다.
즉, 크라와 서버는 요청과 응답을 주고 받고 그때 필요한 데이터를 JSON 형식으로 주고 받는다!
API 문서 열람 서버(백엔드) 개발자와 클라이언트(크라, 프론트, 프론트 엔드) 개발자가 협업하고 있는 회사라면 API 문서가 존재할 것이다.

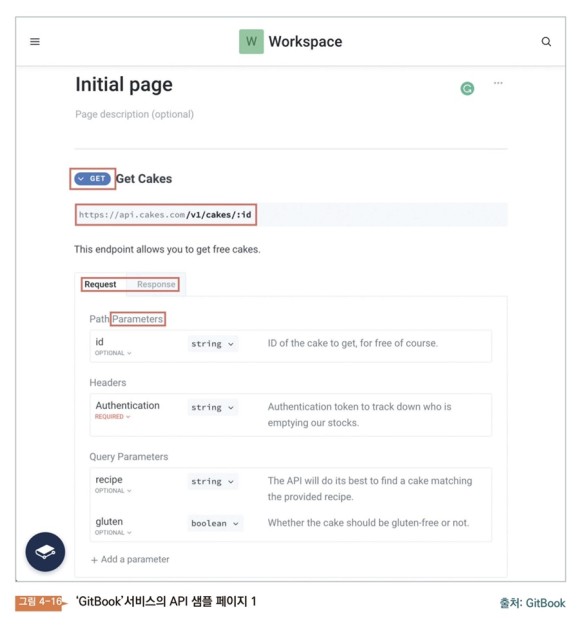
Git Book은 깨끗한 API 문서 작성을 돕는 서비스이다. 해당 서비스가 보여주는 예문서를 보자. Get Cake는 케이크를 달라는 API에 관해 설명하는 문서이다. 아마 실제의 서비스에서는 「회원 정보」나 「타임 라인」과 같은 데이터일 것이다. 구체적으로 차근차근 살펴보자. 일단 파란 GET을 보자 클라가 서버에 요청을 보낼 때 스티커(메소드)를 붙여놓겠다고 했다. GET스티커는 READ를 의미한다.
그리고 https://api.cakes.com/v1/cakes/:id라는 주소가 있다. 앞의 https://api.cakes.com/’은 컴퓨터가 있는 곳이다. 원래 IP 주소가 들어가는 곳이다. 뒤에는 v1/cakes/:id가 있다. 이것은 케이크를 CRUD 하기 위한 주소이다.
그 아래에 요청(request)과 응답(response)이 있다. 그림에서는 response가 선택되었다. 그리고, 배우지 않은 pathparameters, header, queryparameters 가 나와있다. 이 구체적 구분은 기획자의 입장에서 중요하지 않다. 단, 파라미터는 배웠다. 파라미터는 메서드를 보낼 때의 요청 변수이다. 해당 요청을 보내기 위해 어떤 파라미터가 필요한지 확인할 수 있어야 한다.
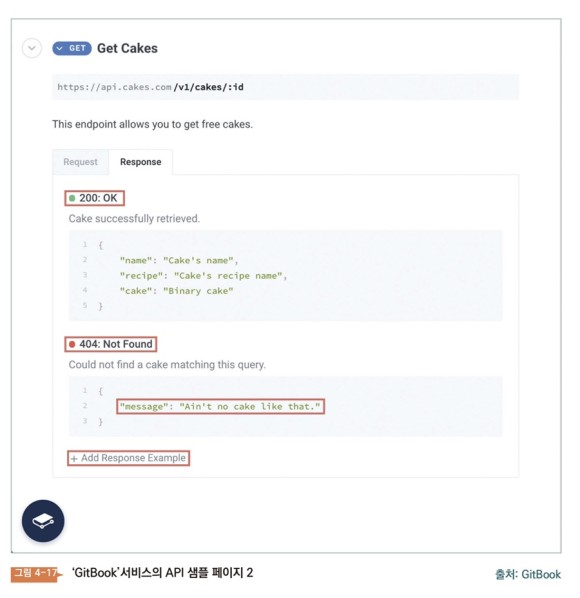
이제 응답(response) 부분을 보자. 대답은 두 가지로 나누어진다. 잘했을경우200번대,못했을경우400번대또는500번대의코드가필요하다. 그리고 답변의 데이터나 메시지를 JSON 형식으로 보내주고 있다.
200번대를 바라보면 케이크 이름, 케이크 레시피, 2진수 케이크 데이터를 보내주고 있다.
404는 서버에 없는 정보를 클라로부터 요구했을 때, 보내 주는 코드이다. 그런 케이크는 없다(aint nocake like that)는 메시지를 보내주고 있다.
+ Add Response Example 버튼을 통해 다른 메시지도 추가할 수 있도록 구성되어 있다. API 문서는 이러한 형태로 구성되어 있다.
- 도메인 네임?IP 주소는 원래 숫자로 구성되어 있다. 175.345.822.402 같은 모습이다. 인터넷에 연결된 컴퓨터는 모두 저런 숫자를 갖고 있다. 요청을 보내려면 저 숫자들을 알아야 해요. 하지만 숫자는 불편하다. 여러분들이 네이버에 접속한다고 생각해보자 네이버 주소가 숫자로 되어 있다면 우리는 그 숫자들을 모두 외워야 한다. 네이버 이외의 수많은 서비스에 접속하기 위해서는 각 서비스의 숫자를 암기해야 한다. 새 서비스 주소를 친구들에게 알려주려면 숫자를 나열해야 한다. 그래서 사람들은 숫자 대신 ‘도메인 네임’이라는 것을 만들었다. www.naver.com 같은 글자다. 의미를가진글자는사람이쉽게외울수있으니까. 도메인 네임만 입력하면 우리가 모르는 사이에 IP로 바뀌어 컴퓨터 위치를 찾는다. 즉 도메인 이름은 IP 주소와 같다.
- 우리가 당장 볼 수 있는 API 문서는 네이버와 카카오 홈페이지에 있다. 네이버에서는 네이버 서버가 제공하는 다양한 기능을 일반인이 사용할 수 있도록 오픈해 놓았다. 개발자들은 네이버가 제공하는 API 문서를 보면서 그 기능을 사용할 수 있다. 이러한 API를 오픈 API라고 한다.
- 그렇다면 왜 네이버는 서버의 기능을 개발자가 쓸 수 있도록 열어 놓았을까? 다른 개발자가 네이버의 기능을 이용해 이용자가 해당 서비스를 사용하면 당연히 네이버 서비스의 영향력이 커진다. 영향력은 힘이고 돈이다. 이와 함께 API 사용의 경우 특정 횟수 이상은 돈을 받기도 한다. 비즈니스 모델이 되어야 한다. 프리미엄 기능에 대한 API를 별도로 정해 놓는 방식으로도 돈을 벌 수 있다. 이렇게 다양한 이유로 회사는 서버의 API를 오픈한다.
- 이로써 여러분은 API 문서를 읽고 이해할 수 있게 됐다. 이해한다는 것은 협업하는 사람에게 많은 것을 묻지 않아도 스스로 진행상황을 파악할 수 있다는 뜻이기도 하다.
- 예를 들어 협업 중인 프로젝트로 회원정보에 생일을 추가하기로 했다. 그러면 회원가입 API와 회원정보 조회 및 수정 API에 대한 변경이 필요하다. 물론 화면도 수정돼야 한다. 화면수정이 끝났는지는 결과물이 분명해 볼 수 있지만 서버 작업이 완료됐는지는 눈에 보이지 않는다. 이 때 API 문서를 읽고 이해할 수 있다면 어느 정도 진전되었는지 스스로 예측할 수 있다.
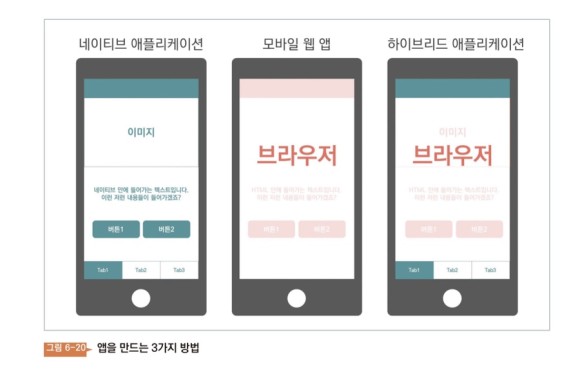
- 5 장. 어플리케이션은 설치하여 사용하는 모든 프로그램이다. 그런데 스마트폰이 등장하면서 앱 애플리케이션이라는 말이 퍼지기 시작하면서 데스크톱에 설치하는 프로그램은 응용프로그램이라고 부르고 스마트폰에 설치하는 프로그램은 앱 혹은 앱이라고 부르게 됐다. 따라서 운영체제 위에 올라가는 프로그램, 설치해야 할 프로그램, 애플리케이션, 앱, 앱이 모두 한 그룹이다.
- 개발자가 앱을 만들 때 ‘1.0.0’과 같이 자신이 개발한 프로그램에 번호를 부여한다. 이 번호를 버전이라고 부른다. 점(.)을 기준으로 숫자가 3부분으로 나뉜다. 일반적으로 오른쪽 끝의 숫자는 작은 변화를 의미한다. 중간 숫자는 하위 버전과 호환이 가능하지만 큰 변화를, 왼쪽 끝은 하위 버전과 호환되지 않는 큰 변화를 뜻한다.
- 6장. Web웹은 HTML, CSS, 자바스크립t로 이루어져 있다.우선 HTML부터 보자.HTML(Hyper Text Markup Language)의 시작은 다음과 같다. 유럽 입자물리연구소에서 일하던 팀 버너스리는 연구소 내 직원들이 수많은 정보를 주고받는 상황에서 문제를 발견했다. 직원들이 서로 다른 OS나 애플리케이션을 사용하기 때문에 각각의 OS에서만 호환되는 파일을 주고받을 때 파일을 열 수 없었다. 이를 해결하기 위해서는 운영체제나 프로그램에 관계없이 일정한 형식이 항상 같아 보이도록 하는 새로운 개념이 필요했다. 그래서 그는 일정 형식(HTML)으로 작성한 문서를 제안했다. HTML 문서는 OS와 상관없이 브라우저만 있으면 스마트폰에서도, PC에서도, 노트북에서도, 윈도에서도, 맥에서도, iOS에서도, 안드로이드에서도 모두 웹사이트에 접속해 같은 정보를 확인할 수 있게 해줬다.
- 이를 통해 모든 정보가 자유롭게 공유되는 세상, 즉 웹을 통해 누구나 쉽게 정보에 접근할 수 있는 오늘의 위키백과 같은 모습을 꿈꾸었다. HTML 코드를 보면 위키백과처럼 정보를 체계화하는 코드가 존재한다. 예를 들어 <h>는 헤더(대제목)를 의미하고, <p>는 Paragraph(단락)를 의미하며, <ol>은 오더 ed List(순서 있는 리스트)를 의미하며, <ul>은 Unordered List(순서 없는 리스트)를 의미한다. 이와 같이 정보를 표현하기 위한 코드를 「태그」라고 부른다. “태그”는 HTML 를 구성하는 코드이다. 태그 중에는 어떤 HTML 문서에서 다른 HTML 문서로 이동할 수 있게 해주는 “a”라는 태그가 있다. 우리에게 익숙한 링크라는 개념이다. 정보를 자유롭게 나누는 목적에 딱 맞는 기능이다. 여기서 주의해야 할 사항은 HTML은 프로그래밍 언어가 아니라는 점이다. HTML은 컴퓨터에 특정한 일을 시킬 수 있는 언어가 아니라 단순히 브라우저가 볼 수 있는 문서를 쓰는 언어이다. 이렇게 만들어진 HTML을 이용해 많은 사람들이 정보를 교환하기 시작했다.시간이 지나면서 사람들은 포토샵이나 일러스트레이터 같은 디자인 기능을 원했기 때문에 HTML에 디자인을 입힐 수 있는 코드인 CSS(Cascading Style Sheets)를 붙였다. 이것에 의해서 HTML 에 디자인을 입힐 수 있게 되었다. 이렇게 코드가 분리되자 HTML 코드는 정보만 표현하고 CSS 코드는 디자인만 표현할 수 있어 깨끗해졌다. 디자인을 수정하고 싶으면 CSS만 찾아 바꾸고 정보를 수정하고 싶으면 HTML 코드만 바꾸면 된다. HTML과 CSS를 합쳐서 “퍼블리싱” 작업이라고 표현한다. 마크업이란 말도 자주 등장한다. 마크업의 M은 HTML의 M을 뜻한다. 즉 HTML 작업을 마크업 작업이라고 부르고 HTML 작업을 주로 하는 사람들을 마크업 개발자라고 부른다.웹이 더 널리 쓰이면서 장바구니 로그인 회원가입 등 다른 기능을 원하는 사람이 늘고 있다. 위의 기능은 HTML 과 CSS 에서는 어려운 기능으로 프로그래밍 언어가 필요하다. 그래서 웹에서는 자바스크립트라고 하는 언어가 프로그래밍 언어 역할을 하게 되었다.
- 검색창에 a를 입력해 보자. 지금은 a3 스틸어라이브가 가장 위에 있지만 2019년 중순 ‘awhole new world 가사’라는 키워드가 가장 상위에 있었다. 그리고 어느 순간 A형 독감이라는 키워드가 가장 위에 있었다. 이 말은 무슨 뜻일까. 검색어를 입력했을 때 나타나는 추천 검색어는 “실시간”으로 구성된다는 뜻이다. 지금 사람들이 가장 많이 검색하는 키워드를 보여준다.
- 그럼 a를 치는 순간, 무슨 일이 일어나는지 설명해 보자.a를 누르면 JavaScript가 “사용자가 a를 쳤다”는 것을 감지한다. 그리고 해당 a에 해당하는 실시간 검색어 목록을 조회하는 API 요청을 네이버 서버로 보낸다. GET 요청이다. 그러면 네이버 서버는 a에 대한 실시간 검색어 목록을 정리하고 답변을 해준다. JSON 형식으로 날아오기 JavaScript 는 그 응답을 열어 HTML 로 바꾼다. 필요하면 CSS도 추가할 수 있다. 그리고 해당하는 부분을 꽂는다. 이 모든 동작은 프로그래밍 언어인 JavaScript 밖에 할 수 없다. HTML 과 CSS 에는 이러한 기능이 없다.

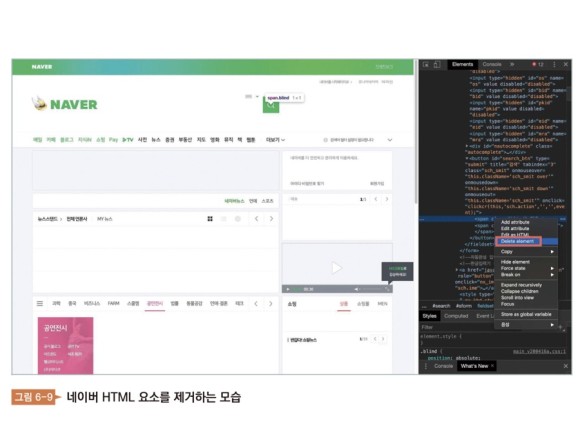
네이버 홈페이지를 한번 부숴보자 HTML 상에서 오른쪽 버튼을 클릭한 후 Delete Elements를 누르면 HTML의 일부를 지울 수 있다. 자세히 보면 검색창과 로그인 버튼이 없고 군데군데 이미지도 없다. 비디오도 없어졌어. 이렇게 body 자체를 없애면 모든 화면을 날릴 수도 있다. 글쎄, 어떤 일이 벌어질까? 경찰에서 전화가 올까? 네이버 홈페이지를 망가뜨린 죄로 벌금을 낼까? 아니야 아무 일도 안 일어나 내가 HTML을 삭제한 건 의미 없는 행동이니까. 이것이 웹의 가장 큰 특징이다.
HTM, CSS, 자바스크립트의 완성본은 모두 서버에 있다. 위로부터 GET 요청으로 HTML 문서를 받아왔다. 서버에 있는 HTML 문서를 불러온 것이다. 그렇게 HTML을 읽은 뒤 HTML과 연결된 CSS, avaScript, 이미지, 글꼴, 동영상 등의 파일을 다시 내려받는다. 즉, 여러분의 컴퓨터에 있는 HTML, CSS, javaScript 는 모두 복사본이다. 네이버 홈페이지를 망가뜨린 것은 서버 원본을 건드린 것이 아니라 자신의 컴퓨터에서 내려받은 HTML 복사본의 일부분을 삭제한 것이다. 새로 고침하면 다시 HTML 원본에서 다운로드 받는다. 그리고, CSS, JavaScript 등도 재다운로드한다. 이 부분이 웹과 앱을 나누는 가장 큰 차이다.
앱을 1.0.0에서 2.0.0으로 변경하기 위해서는 업데이트가 필요하다. 모바일이라면 심사도 필요하다. 그렇게 업데이트 된 결과를 사용자가 다운로드 해야 한다. 그래야 변화가 반영된다. 그러나 웹은 다르다. 웹은 서버의 원본을 그대로 바꾸면 되며, 「갱신」시에 바뀐 HTML, CSS, 자바스크립t, 화상등의 파일이 재다운로드 된다. 심사 과정도 없고 사용자의 업데이트 과정도 필요 없다. 새로 고침하면 자동으로 모두 반영된다.
웹과 앱은 각각 장단점이 있다. 우선 웹은 수정이 용이하다. 원본만 수정하면 사용자가 업데이트 하지 않아도 다시 쓰면 반영된다. 빠르게 적용할 수 있다. 하지만 앱은 다르다. 너무 오래 걸린다. 재미있는 것은 웹의 장점이었던 ‘ 새로고침’이 단점이기도 하다는 점이다. 웹은 항상 새로고침을 해야 한다. 즉, 매번 HTML, CSS, 자바스크립트를 다운로드 받아야 한다. 웹은 네트워크가 빠른 환경이면 괜찮다. 그러나 우리가 사는 세상 네트워크가 항상 빠른 것은 아니다. 사람이 많은 곳에 가면 인터넷이 마비된다. 웹은 이 네트워크의 영향을 크게 받는다. 반면 앱은 웹보다 효율적으로 네트워크의 영향을 적게 받도록 할 수 있다. 대표적인 앱은 카카오톡이다. 카카오톡은 대화 내용을 여러분의 기기(스마트폰, 노트북 등)에 저장한다. 새로운 대화만 자아내다. 그래서 카카오톡을 쓰다 보면 용량이 너무 커져 대화방을 나가야 하는 경우가 있다. 대화방을 나가면 저장된 대화를 없애 용량을 확보할 수 있다. 이런 방식으로 카카오톡은 속도감 있는 이슈를 해결했다. 다른 대표적인 앱은 에버노트가 있다. 에버노트는 오프라인에서도 노트를 만들 수 있다. 그리고 온라인 상태가 되면 ‘동기화’가 이루어진다. 인터넷에 관계없이 서비스를 이용할 수 있게 한 것이다.
웹 개발자들이 못해 먹겠다고 말하는 이유는 5개 브라우저(크롬 익스플로러 오페라 파이어폭스 사파리)가 세계에서 가장 큰 점유율을 차지하는 브라우저다. 우선, 이러한 브라우저는 HTML, CSS, JavaScript 를 취득해 읽는다. 그리고, HTML 에 쓰여진 정보를 표시해, CSS에 쓰여진 대로 디자인을 해, JavaScript 에 쓰여진 대로 동작한다. 그게 브라우저의 일이다.
그러나 크롬과 같은 브라우저는 익스플로러 또는 사파리에 들어가 다운받아 설치할 수 있다. 그래야 크롬을 실행할 수 있다. 다운로드와 설치가 필요하다는 것은 크롬이 애플리케이션이라는 것이다. 다른 브라우저도 마찬가지다. 모두 어플리케이션이다. 즉, 어플리케이션은 사용하는 사람마다 버전이 다를 수 있다. 그리고 브라우저 자체도 다를 수 있다.
이게 왜 문제가 될까? 생각해보자 인터넷 익스플로러 4 버전은 CSS 2에서 추가된 기능을 알 수 있나? 혹은 인터넷 익스플로러8 버전에서 HTML 5의 기능이 정상으로 돌아오는지? 대답은 아니다. 여기서 문제가 발생한다. 각 브라우저는 다른 어플리케이션이므로 브라우저에 따라 그 안의 구현 방식이 다르다. 즉, HTML, CSS, JavaScript의 특정 기능이 버전별, 브라우저별로 동작할 수도 있고 동작할 수도 있다. 누구는 인터넷 익스플로러를 쓰고, 누구는 크롬을 쓰고, 누구는 사파리를 사용하는 복잡한 상황에서 웹프런트 개발자는 소비자의 브라우저 버전과 종류에 따라 정상적으로 작동할 수 있도록 추가로 코드를 만들어야 한다. 이 문제를 ‘브라우저판의 파편화’라고 부르며, 문제 해결을 위한 코딩을 ‘파편화를 잡는다’고 표현한다. 클라이언트, 웹프런트 엔드, 퍼블리싱 작업을 하는 사람들이 힘들어하는 주된 이유 중 하나이다.
벌써 이런 생각이 들 거야.”아니, 그 많은 브라우저의 파편화를 어떻게 찍어?” “모든 걸 만족시킬 필요는 없어. 중요한 것은 「쉐어」다. 국내 서비스라면 국내 이용자 점유율을 더 조사해 계산해 봐야 한다.
반응형으로 코딩하면 더 높은 거예요?과거의 모니터는 비슷비슷했다. 그래서 웹 페이지를 개발하는 사람들은 “웹 페이지를 만들 때 양쪽을 잘라 적절한 해상도를 맞추면 모두 똑같이 보일 것이다!”라고 생각했다. 이런 이유로 과거 웹페이지는 양쪽 끝이 잘려 가운데 콘텐츠가 모여 있는 형태로 디자인됐다. 하지만 시간이 흐른 뒤 스마트폰과 태블릿이 등장하면서 문제가 생겼다. 스마트폰으로 ‘PC 버전 웹’을 보니 화면이 끊어져 보이는 것이었다. 오른쪽으로 넘겨 확대/축소해 불편하게 웹을 확인할 필요가 있었다.
그래서 네이버, 다음과 같은 업체는 m. m.daum.net m.daum.net처럼 주소 앞에 m이 붙어 있는 모바일용 웹페이지를 따로 만들었다. 하지만 모바일과 PC 버전의 웹을 따로 만들어 내놓는 것은 불편하다. 디자인을 바꾸기 위해서는 서로 다른 CSS 파일을 수정해야 하기 때문이다. 내용을 수정해야 한다면 HTML을 두 번 수정해야 한다. 작업이 중복되기 때문에 비효율적이고 오류가 발생할 수도 있다.
이런 불편을 해결하기 위해 등장한 기술이 반응형 웹이다. 브라우저의 가로 폭에 ‘반응’하여 구성요소가 바뀌는 기술이다. 이전에는 가로 넓이가 특정 픽셀 이하로 내려가거나 위로 올라가면 각기 다른 CSS를 적용해야 했다. 하지만 반응형 기술을 활용하면 공통으로 사용하는 CSS 코드는 그대로 두고 레이아웃 중심으로 나눠 작업하는 기기의 디자인을 구현할 수 있다. 즉, 웹 페이지의 크기(비율)가 사용자의 기기에 맞추어 자동적으로 변형된다는 의미이다. 그러기 위해서는 다른 기기의 폭에 따른 CSS를 추가 코딩할 필요가 있다. 당연히 한 폭으로 작업하는 것보다 많은 코드가 필요하다. 따라서 반응형으로 웹을 만드는 데는 작업 시간이 오래 걸리고 비용이 더 들 수 있다.
어플리케이션 얘기하는데 왜 자꾸 웹 개발자에게 얘기하라고?iOS 프로그램을 개발하기 위한 프로그래밍 언어는 스위프트, Objective-C이다. 안드로이드 프로그램을 개발하기 위한 프로그래밍 언어는 자바, 코토린이다. 이들 언어로 개발된 앱을 원어민 앱이라고 한다. 원래 정해진 언어를 사용해 운영체제 자체의 기능을 사용하기 때문에 원주민이라는 뜻의 원어민이 붙는 셈이다.
네이버 홈페이지를 한번 부숴보자 HTML 상에서 오른쪽 버튼을 클릭한 후 Delete Elements를 누르면 HTML의 일부를 지울 수 있다. 자세히 보면 검색창과 로그인 버튼이 없고 군데군데 이미지도 없다. 비디오도 없어졌어. 이렇게 body 자체를 없애면 모든 화면을 날릴 수도 있다. 글쎄, 어떤 일이 벌어질까? 경찰에서 전화가 올까? 네이버 홈페이지를 망가뜨린 죄로 벌금을 낼까? 아니야 아무 일도 안 일어나 내가 HTML을 삭제한 건 의미 없는 행동이니까. 이것이 웹의 가장 큰 특징이다.
HTM, CSS, 자바스크립트의 완성본은 모두 서버에 있다. 위로부터 GET 요청으로 HTML 문서를 받아왔다. 서버에 있는 HTML 문서를 불러온 것이다. 그렇게 HTML을 읽은 뒤 HTML과 연결된 CSS, avaScript, 이미지, 글꼴, 동영상 등의 파일을 다시 내려받는다. 즉, 여러분의 컴퓨터에 있는 HTML, CSS, javaScript 는 모두 복사본이다. 네이버 홈페이지를 망가뜨린 것은 서버 원본을 건드린 것이 아니라 자신의 컴퓨터에서 내려받은 HTML 복사본의 일부분을 삭제한 것이다. 새로 고침하면 다시 HTML 원본에서 다운로드 받는다. 그리고, CSS, JavaScript 등도 재다운로드한다. 이 부분이 웹과 앱을 나누는 가장 큰 차이다.
앱을 1.0.0에서 2.0.0으로 변경하기 위해서는 업데이트가 필요하다. 모바일이라면 심사도 필요하다. 그렇게 업데이트 된 결과를 사용자가 다운로드 해야 한다. 그래야 변화가 반영된다. 그러나 웹은 다르다. 웹은 서버의 원본을 그대로 바꾸면 되며, 「갱신」시에 바뀐 HTML, CSS, 자바스크립t, 화상등의 파일이 재다운로드 된다. 심사 과정도 없고 사용자의 업데이트 과정도 필요 없다. 새로 고침하면 자동으로 모두 반영된다.
웹과 앱은 각각 장단점이 있다. 우선 웹은 수정이 용이하다. 원본만 수정하면 사용자가 업데이트 하지 않아도 다시 쓰면 반영된다. 빠르게 적용할 수 있다. 하지만 앱은 다르다. 너무 오래 걸린다. 재미있는 것은 웹의 장점이었던 ‘ 새로고침’이 단점이기도 하다는 점이다. 웹은 항상 새로고침을 해야 한다. 즉, 매번 HTML, CSS, 자바스크립트를 다운로드 받아야 한다. 웹은 네트워크가 빠른 환경이면 괜찮다. 그러나 우리가 사는 세상 네트워크가 항상 빠른 것은 아니다. 사람이 많은 곳에 가면 인터넷이 마비된다. 웹은 이 네트워크의 영향을 크게 받는다. 반면 앱은 웹보다 효율적으로 네트워크의 영향을 적게 받도록 할 수 있다. 대표적인 앱은 카카오톡이다. 카카오톡은 대화 내용을 여러분의 기기(스마트폰, 노트북 등)에 저장한다. 새로운 대화만 자아내다. 그래서 카카오톡을 쓰다 보면 용량이 너무 커져 대화방을 나가야 하는 경우가 있다. 대화방을 나가면 저장된 대화를 없애 용량을 확보할 수 있다. 이런 방식으로 카카오톡은 속도감 있는 이슈를 해결했다. 다른 대표적인 앱은 에버노트가 있다. 에버노트는 오프라인에서도 노트를 만들 수 있다. 그리고 온라인 상태가 되면 ‘동기화’가 이루어진다. 인터넷에 관계없이 서비스를 이용할 수 있게 한 것이다.
웹 개발자들이 못해 먹겠다고 말하는 이유는 5개 브라우저(크롬 익스플로러 오페라 파이어폭스 사파리)가 세계에서 가장 큰 점유율을 차지하는 브라우저다. 우선, 이러한 브라우저는 HTML, CSS, JavaScript 를 취득해 읽는다. 그리고, HTML 에 쓰여진 정보를 표시해, CSS에 쓰여진 대로 디자인을 해, JavaScript 에 쓰여진 대로 동작한다. 그게 브라우저의 일이다.
그러나 크롬과 같은 브라우저는 익스플로러 또는 사파리에 들어가 다운받아 설치할 수 있다. 그래야 크롬을 실행할 수 있다. 다운로드와 설치가 필요하다는 것은 크롬이 애플리케이션이라는 것이다. 다른 브라우저도 마찬가지다. 모두 어플리케이션이다. 즉, 어플리케이션은 사용하는 사람마다 버전이 다를 수 있다. 그리고 브라우저 자체도 다를 수 있다.
이게 왜 문제가 될까? 생각해보자 인터넷 익스플로러 4 버전은 CSS 2에서 추가된 기능을 알 수 있나? 혹은 인터넷 익스플로러8 버전에서 HTML 5의 기능이 정상으로 돌아오는지? 대답은 아니다. 여기서 문제가 발생한다. 각 브라우저는 다른 어플리케이션이므로 브라우저에 따라 그 안의 구현 방식이 다르다. 즉, HTML, CSS, JavaScript의 특정 기능이 버전별, 브라우저별로 동작할 수도 있고 동작할 수도 있다. 누구는 인터넷 익스플로러를 쓰고, 누구는 크롬을 쓰고, 누구는 사파리를 사용하는 복잡한 상황에서 웹프런트 개발자는 소비자의 브라우저 버전과 종류에 따라 정상적으로 작동할 수 있도록 추가로 코드를 만들어야 한다. 이 문제를 ‘브라우저판의 파편화’라고 부르며, 문제 해결을 위한 코딩을 ‘파편화를 잡는다’고 표현한다. 클라이언트, 웹프런트 엔드, 퍼블리싱 작업을 하는 사람들이 힘들어하는 주된 이유 중 하나이다.
벌써 이런 생각이 들 거야.”아니, 그 많은 브라우저의 파편화를 어떻게 찍어?” “모든 걸 만족시킬 필요는 없어. 중요한 것은 「쉐어」다. 국내 서비스라면 국내 이용자 점유율을 더 조사해 계산해 봐야 한다.
반응형으로 코딩하면 더 높은 거예요?과거의 모니터는 비슷비슷했다. 그래서 웹 페이지를 개발하는 사람들은 “웹 페이지를 만들 때 양쪽을 잘라 적절한 해상도를 맞추면 모두 똑같이 보일 것이다!”라고 생각했다. 이런 이유로 과거 웹페이지는 양쪽 끝이 잘려 가운데 콘텐츠가 모여 있는 형태로 디자인됐다. 하지만 시간이 흐른 뒤 스마트폰과 태블릿이 등장하면서 문제가 생겼다. 스마트폰으로 ‘PC 버전 웹’을 보니 화면이 끊어져 보이는 것이었다. 오른쪽으로 넘겨 확대/축소해 불편하게 웹을 확인할 필요가 있었다.
그래서 네이버, 다음과 같은 업체는 m. m.daum.net m.daum.net처럼 주소 앞에 m이 붙어 있는 모바일용 웹페이지를 따로 만들었다. 하지만 모바일과 PC 버전의 웹을 따로 만들어 내놓는 것은 불편하다. 디자인을 바꾸기 위해서는 서로 다른 CSS 파일을 수정해야 하기 때문이다. 내용을 수정해야 한다면 HTML을 두 번 수정해야 한다. 작업이 중복되기 때문에 비효율적이고 오류가 발생할 수도 있다.
이런 불편을 해결하기 위해 등장한 기술이 반응형 웹이다. 브라우저의 가로 폭에 ‘반응’하여 구성요소가 바뀌는 기술이다. 이전에는 가로 넓이가 특정 픽셀 이하로 내려가거나 위로 올라가면 각기 다른 CSS를 적용해야 했다. 하지만 반응형 기술을 활용하면 공통으로 사용하는 CSS 코드는 그대로 두고 레이아웃 중심으로 나눠 작업하는 기기의 디자인을 구현할 수 있다. 즉, 웹 페이지의 크기(비율)가 사용자의 기기에 맞추어 자동적으로 변형된다는 의미이다. 그러기 위해서는 다른 기기의 폭에 따른 CSS를 추가 코딩할 필요가 있다. 당연히 한 폭으로 작업하는 것보다 많은 코드가 필요하다. 따라서 반응형으로 웹을 만드는 데는 작업 시간이 오래 걸리고 비용이 더 들 수 있다.
어플리케이션 얘기하는데 왜 자꾸 웹 개발자에게 얘기하라고?iOS 프로그램을 개발하기 위한 프로그래밍 언어는 스위프트, Objective-C이다. 안드로이드 프로그램을 개발하기 위한 프로그래밍 언어는 자바, 코토린이다. 이들 언어로 개발된 앱을 원어민 앱이라고 한다. 원래 정해진 언어를 사용해 운영체제 자체의 기능을 사용하기 때문에 원주민이라는 뜻의 원어민이 붙는 셈이다.
하지만 운영체제 내에 브라우저가 들어가자 새로운 방식으로도 앱 개발이 가능해졌다. 앱의 특정 부분에 브라우저를 올리는 방식이다. 그리고 HTML 파일을 불러올 URL을 설정해 둔다. 그러면 브라우저가 나타나고 해당 브라우저는 HTML과 HTML에 연결된 파일을 가져와 보여준다. 그 부분은 HTML, CSS, JavaScript로 구성되어 있다. 네이티브와 브라우저가 혼합된 어플리케이션이다. 이렇게 애플리케이션이 혼합된 앱을 하이브리드 앱이라고 한다.
이런 하이브리드 앱을 수정하려면 어떻게 하면 좋은 것일까. 브라우저상으로 돌아가는 부분은 서버에 있는 원본 HTML, CSS, 자바 스크립t를 수정하면 바뀐다. 이 부분은 보통 앱 화면이 뜨면 바뀐다. 반면 원어민 부분은 운영체제별로 다른 프로그래밍 언어로 수정해 심사를 신청해야 한다. 심사 신청 후에도 사람들이 바뀐 앱으로 업데이트해야 한다. 아무래도 시간이 걸려 까다롭다.
HTML, CSS, JavaScrip을 가져와서 표시하는 방법은 수정하기 쉽다. 서버의 HTML, CSS, JavaScrip만 수정하면 별도의 심사를 받거나 설치할 필요 없이 새로 고침할 때 반영된다. 하지만 네트워크에 종속되므로 Wi-Fi나 모바일 네트워크가 느린 공간에 가면 HTML, CSS, 자바스크rip을 모두 내려받는 동안 사용자는 기다려야 한다. 이용자가 불편을 느끼면 서비스를 떠날 수밖에 없다.
반면 원어민이 만들면 수정하는 데 넘어야 할 산이 많다는 단점이 있다. 특히 iOS 심사는 큰 장벽 중 하나이다. 게다가 심사가 끝나도 사용자가 직접 업데이트해야 한다. 이용자 입장에서 너무 잦은 업데이트는 귀찮다. 물론 잘 만든 앱은 사용하기 편리하다는 장점이 있다. 네트워크를 최소한으로 이용하도록 코딩하면 인터넷이 느린 환경에서도 빠르게 작동한다.
이제 우리에게 남은 과제는 어느 부분이 웹이고 어느 부분이 원어민 앱인지를 구별하는 일이다. 그래야 문제가 생겼을 때 적합한 개발자에게 물을 수 있다. 결론부터 말하면 이 두 가지를 확연히 구분할 방법은 없다. 하지만 어느 정도 힌트는 있다. 그것은 API 문서를 보는 것이다. API 문서에는 웹 개발자를 위한 부분과 앱 개발자를 위한 부분이 구분되어 있다. 물론 이들이 함께 사용하는 API의 경우에는 별다른 표시가 없을 수도 있다.
7장: 데이터베이스와 이미지 처리 “크라에 저장됩니다”, “크라가 가지고 있습니다”, “대체크라가 가지고 있다는 것은 무엇?” 우리는 CPU, 메모리, 보조 기억 장치라는 하드웨어에 대해 배웠다. CPU는 컴퓨터의 머리, 보조기억장치는 컴퓨터의 창고이다. 메모리는 CPU의 개인 작업공간이다. 그러나 메모리에 저장된 데이터는 전원이 꺼지면 꺼진다.
지금 생각해 보자. 데이터는 CPU, 메모리, 보조기억장치 중 어디에 저장되는가? 당연히 보조기억장치에 저장된다. 한편 데이터베이스 관리시스템(DBMS)은 소프트웨어다. 우리는 ‘네트워크’에서 두 개의 서로 다른 컴퓨터 그룹을 배웠다. ‘클라이언트’와 ‘서버’이다. 클라이언트와 서버는 모두 컴퓨터이기 때문에 CPU, 메모리, 보조기억장치를 가지고 있다. 그러면 크라토 서버의 컴퓨터 위에는 모든 데이터베이스 관리 시스템을 돌릴 수 있고, 데이터를 저장할 수 있다. 그 때문에 데이터는 쿠라에도 보존할 수 있다. 서버에서만 DB를 사용하는 것처럼 알고 있는 사람들이 많지만 실제로는 그렇지 않다. 개발 이슈에 따라 크라 DB도 많이 활용한다.
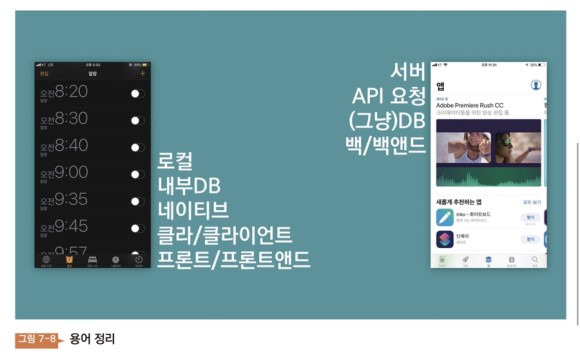
그러면 DB가 클래에 저장되어 있는지 서버에 저장되어 있는지를 어떻게 알 수 있을까? 인터넷이 연결되어 있지 않은 상태에서도 동작하면 클래에 있는 DB이다. 서버와 통신하지 않아도 정상적으로 동작하기 위해. 알람 앱에서는 서버를 필요로 하지 않기 때문에, 그 데이터도 클라이언트에 있다.
하지만 운영체제 내에 브라우저가 들어가자 새로운 방식으로도 앱 개발이 가능해졌다. 앱의 특정 부분에 브라우저를 올리는 방식이다. 그리고 HTML 파일을 불러올 URL을 설정해 둔다. 그러면 브라우저가 나타나고 해당 브라우저는 HTML과 HTML에 연결된 파일을 가져와 보여준다. 그 부분은 HTML, CSS, JavaScript로 구성되어 있다. 네이티브와 브라우저가 혼합된 어플리케이션이다. 이렇게 애플리케이션이 혼합된 앱을 하이브리드 앱이라고 한다.
이런 하이브리드 앱을 수정하려면 어떻게 하면 좋은 것일까. 브라우저상으로 돌아가는 부분은 서버에 있는 원본 HTML, CSS, 자바 스크립t를 수정하면 바뀐다. 이 부분은 보통 앱 화면이 뜨면 바뀐다. 반면 원어민 부분은 운영체제별로 다른 프로그래밍 언어로 수정해 심사를 신청해야 한다. 심사 신청 후에도 사람들이 바뀐 앱으로 업데이트해야 한다. 아무래도 시간이 걸려 까다롭다.
HTML, CSS, JavaScrip을 가져와서 표시하는 방법은 수정하기 쉽다. 서버의 HTML, CSS, JavaScrip만 수정하면 별도의 심사를 받거나 설치할 필요 없이 새로 고침할 때 반영된다. 하지만 네트워크에 종속되므로 Wi-Fi나 모바일 네트워크가 느린 공간에 가면 HTML, CSS, 자바스크rip을 모두 내려받는 동안 사용자는 기다려야 한다. 이용자가 불편을 느끼면 서비스를 떠날 수밖에 없다.
반면 원어민이 만들면 수정하는 데 넘어야 할 산이 많다는 단점이 있다. 특히 iOS 심사는 큰 장벽 중 하나이다. 게다가 심사가 끝나도 사용자가 직접 업데이트해야 한다. 이용자 입장에서 너무 잦은 업데이트는 귀찮다. 물론 잘 만든 앱은 사용하기 편리하다는 장점이 있다. 네트워크를 최소한으로 이용하도록 코딩하면 인터넷이 느린 환경에서도 빠르게 작동한다.
이제 우리에게 남은 과제는 어느 부분이 웹이고 어느 부분이 원어민 앱인지를 구별하는 일이다. 그래야 문제가 생겼을 때 적합한 개발자에게 물을 수 있다. 결론부터 말하면 이 두 가지를 확연히 구분할 방법은 없다. 하지만 어느 정도 힌트는 있다. 그것은 API 문서를 보는 것이다. API 문서에는 웹 개발자를 위한 부분과 앱 개발자를 위한 부분이 구분되어 있다. 물론 이들이 함께 사용하는 API의 경우에는 별다른 표시가 없을 수도 있다.
7장: 데이터베이스와 이미지 처리 “크라에 저장됩니다”, “크라가 가지고 있습니다”, “대체크라가 가지고 있다는 것은 무엇?” 우리는 CPU, 메모리, 보조 기억 장치라는 하드웨어에 대해 배웠다. CPU는 컴퓨터의 머리, 보조기억장치는 컴퓨터의 창고이다. 메모리는 CPU의 개인 작업공간이다. 그러나 메모리에 저장된 데이터는 전원이 꺼지면 꺼진다.
지금 생각해 보자. 데이터는 CPU, 메모리, 보조기억장치 중 어디에 저장되는가? 당연히 보조기억장치에 저장된다. 한편 데이터베이스 관리시스템(DBMS)은 소프트웨어다. 우리는 ‘네트워크’에서 두 개의 서로 다른 컴퓨터 그룹을 배웠다. ‘클라이언트’와 ‘서버’이다. 클라이언트와 서버는 모두 컴퓨터이기 때문에 CPU, 메모리, 보조기억장치를 가지고 있다. 그러면 크라토 서버의 컴퓨터 위에는 모든 데이터베이스 관리 시스템을 돌릴 수 있고, 데이터를 저장할 수 있다. 그 때문에 데이터는 쿠라에도 보존할 수 있다. 서버에서만 DB를 사용하는 것처럼 알고 있는 사람들이 많지만 실제로는 그렇지 않다. 개발 이슈에 따라 크라 DB도 많이 활용한다.
그러면 DB가 클래에 저장되어 있는지 서버에 저장되어 있는지를 어떻게 알 수 있을까? 인터넷이 연결되어 있지 않은 상태에서도 동작하면 클래에 있는 DB이다. 서버와 통신하지 않아도 정상적으로 동작하기 위해. 알람 앱에서는 서버를 필요로 하지 않기 때문에, 그 데이터도 클라이언트에 있다.
앱스토어를 보자. 앱스토어에도 다양한 데이터가 있다. ‘Adobe Premiere Ruch CC’라는 텍스트가 있어 이 데이터는 어디에 있는 데이터일까. 서버인가? 크라이인가? 답은 서버다. 왜 그럴까?이 데이터는 어느 스마트폰으로 접속해도 똑같이 보인다. 데이터가 서버에 있기 때문에 데이터를 변경하려면 다른 모든 기기에 변경된 데이터가 나타난다.
그러나 개발 결과물만 보고 항상 명확하게 클래스에 있는 데이터/서버에 있는 데이터와 구분할 수는 없다. 회사 사정에 따라, 개발자 상황에 따라, 개발 단계에 따라, 기능 특성에 따라 경우가 달라진다. 그러나 API 문서에는 거의 모든 답이 담겨 있다. 이 문서를 읽어 보면 데이터를 어디서부터 읽어야 하는지 알 수 있다. 우리는 개발팀의 사정과 상황에 무관심해서는 안 되며 회사의 개발 결과물을 잘 파악하고 있어야 한다. 아울러 현재 개발팀이 어디에 집중돼 있는지, 어떤 부분에서 막혀 있는지를 파악해야 한다. 그 시초가 API 문서다.
우리에게 남겨진 과제는, 서비스의 어떠한 데이터를 서버로부터 읽을지, 어떠한 데이터가 클라이언트에 있는지를 구별하는 것이다. 때로는 양쪽 모두 데이터가 있는 경우도 있다. Like 에버노트 이 앱은 클라이언트의 데이터와 서버의 데이터를 맞추는 「동기화」라고 하는 프로세스가 필요하다. 에버노트는 클래에 데이터를 두기 때문에 오프라인 상태에서도 노트를 쓸 수 있다. 그리고 서버에도 데이터를 두기 때문에 다른 기기에서도 같은 노트의 내용을 볼 수 있다.
그렇다면 이 구분은 왜 중요한가. 그 이유는 정확한 사람에게 정확히 요청하기 위해서이다. 데이터가 클라라에 있는 상황에서 그 데이터를 변경하려면 당연히 클라이언트 개발자와 이야기를 해야 한다. 한편 데이터가 서버에 있는 상황에서 그 데이터를 변경하고 싶다면 당연히 서버 개발자와 이야기해야 한다.

“그 데이터는 로컬에 있습니다.” “내부 DB에 저장하고 있습니다.” “원어민에서 가져온 것인데?” “이 말들이 들리면 모든 고객에게 데이터가 있다는 표현이다.
API로 가져왔어요.DB에 저장해 쓰면 안 돼요?”한편 ‘Server, API, DB, 백/백엔드’와 같은 표현은 ‘Server에서 데이터를 가져왔다’는 뜻이다. 여기서 DB와 내부 DB만 잘 구분하면 된다.
배너를 바꾸려고 하는데 자꾸 자기한테 말하면 안 된대.왜 자꾸 사람이 변해?마케팅 캠페인을 위한 배너디자인을 완성했다. 서둘러 iOS 개발자를 찾아간다.이 배너는 새로운 캠페인 배너로 바꿔주세요. 되게 중요하고 초조해요!”
그럼 iOS 개발자는 말한다.배너의 이미지는 서버에서 받아왔습니다. 서버 개발자에게 말해라.
지난번에는 앱 아이콘을 수정하는 작업을 위해 서버 개발자를 찾아갔다.아이콘을 새롭게 바꾸고 싶습니다.”
그런데 서버 개발자는 이렇게 얘기하더군요.” 아이콘은 클라에 있거든요. 쿠라 개발자에게 말해주세요”
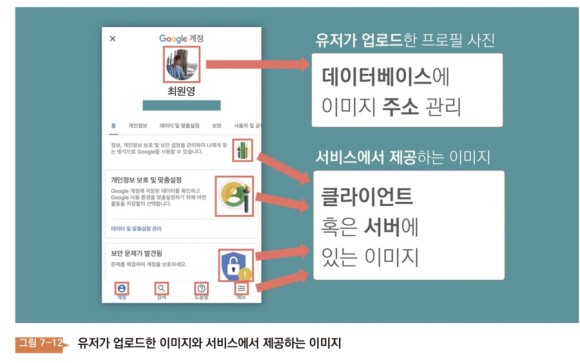
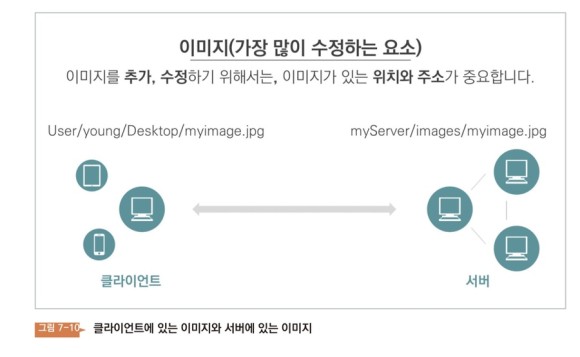
아니, 도대체 왜 사람이 계속 바뀌는 거지? 무엇보다도, 어떤 요소가 서버에 있는지, 클래에 있는지, 비전공자가 어떻게 알 수 있는지? 그리고 이미지는 도대체 어떻게 관리하는 거지?윈도우를 보자. 데스크탑에 이미지가 있다. 이 사진의 이름은 myimage.png이다. 이 상황에서 전혀 다른 이미지를 다운로드한다. 그리고 같은 바탕화면에 놓는다. 이름을 「myimage.png」로 바꾸면, 바뀔까? 변하지 않는다 이미 그 위치에 존재하는 이름이기 때문이다 이미지 상에서 마우스 오른쪽 버튼을 누르면 ‘프로퍼티’라는 메뉴가 있다. 속성’ 을 누르면 이미지 정보가 나타난다.
그 정보에는 「위치」가 있다.User/young/Desktop/myimage.png 이런 모습이다. 위치는 고유해야 한다. 왜 그럴까? 운영체제가 그 고유의 위치를 통해 이미지를 인식하기 때문이다. 이제 우리는 이미지 파일에는 모두 위치가 있음을 알고 있다. 지금부터 이 위치를 ‘주소’라고 표현해 보자.
컴퓨터라면 모두 이미지 파일을 저장할 수 있다. 즉, 클라에도 이미지 파일이 있을 수 있고 서버에도 이미지 파일이 있을 수 있다. 그들은 모두 주소를 갖고 있다는 사실을 알고 있다. 그러면 당연히 서버에서 이미지를 공유하고, 클라가 이미지의 주소를 알고 있으면 서버에 있는 이미지를 클라에서 불러낼 수 있다. 클라에서 서버에 있는 이미지를 읽는다는 것은 네트워크를 통해 이미지 파일을 다운받는다는 것을 의미한다.
이미지 파일의 크기는 어느 정도인가? 작은 이미지도 있지만, 하나는 100MB를 넘는 큰 이미지도 있다. 그런 이미지를 내려받으려면 엄청난 시간이 걸린다. 고객은 기다려야 한다. 인터넷이 느린 곳이면 더 심할 거야 쿠라에게 이미지를 주면 더 장점이 있어 이미지를 다운로드하지 않아도 된다. 클라이언트 프로그램이 이미지 주소를 통해서 이미지를 취득한다. 네트워크보다 훨씬 빠르다.
그럼 서버에 있는 이미지를 왜 읽지? 그냥 꾸라에 이미지 두고 쓰면 안 되나? 쿠라의 이미지는 어떻게 바꿀까. 클래의 이미지를 바꾸려면 앱을 업데이트 할 필요가 있어. 버전 1.0.0에서 이미지 1을 보여줬다고 가정해 보자. 만약 버전이 1.0.1로 상승하여 ‘이미지 2’를 표시하게 되면 고객이 업데이트하여 앱의 버전을 올려야 한다. 만약 업데이트를 하지 않고 버전 1.0.0을 사용하는 고객이라면 「이미지 2」는 보이지 않는다.그럼 어떻게 해야 할까.상황에 따라 둘 다 사용해야 한다.최대한 네트워크에 부담을 주지 않도록 많은 이미지를 크랙에 둘 필요가 있지만 이미지가 바뀌었을 때 서비스에 영향을 준다면 서버부터 빼내야 한다. 즉, 클래스에 둘지 서버에 둘지를 결정하기 위해서는 이미지의 성격을 봐야 한다.조금 다른 이미지도 생각해보자 이미지를 만드는 주체는 「회사」에서도 「고객」일 수 있다. 인스타그램에는 많은 고객이 매일 많은 이미지를 업로드한다. 일반적인 다른 서비스에서도 고객은 자신의 프로필 사진을 업로드 한다. 이런 이미지는 고객이 만들어낸다. 즉 누가 어떤 이미지를 만들었는지 관계가 생긴다. 서로 관계가 맺어진 데이터는 단 0.000001%의 오류도 허용하지 않는 완전성의 문제가 있다. 누군가가 올린 프로필 사진이 다른 사람의 프로필에 보여서는 안 되게. 누군가 비공개로 올린 사진이 공개되지 않도록. 관리가 필요하다.
“그 데이터는 로컬에 있습니다.” “내부 DB에 저장하고 있습니다.” “원어민에서 가져온 것인데?” “이 말들이 들리면 모든 고객에게 데이터가 있다는 표현이다.
API로 가져왔어요.DB에 저장해 쓰면 안 돼요?”한편 ‘Server, API, DB, 백/백엔드’와 같은 표현은 ‘Server에서 데이터를 가져왔다’는 뜻이다. 여기서 DB와 내부 DB만 잘 구분하면 된다.
배너를 바꾸려고 하는데 자꾸 자기한테 말하면 안 된대.왜 자꾸 사람이 변해?마케팅 캠페인을 위한 배너디자인을 완성했다. 서둘러 iOS 개발자를 찾아간다.이 배너는 새로운 캠페인 배너로 바꿔주세요. 되게 중요하고 초조해요!”
그럼 iOS 개발자는 말한다.배너의 이미지는 서버에서 받아왔습니다. 서버 개발자에게 말해라.
지난번에는 앱 아이콘을 수정하는 작업을 위해 서버 개발자를 찾아갔다.아이콘을 새롭게 바꾸고 싶습니다.”
그런데 서버 개발자는 이렇게 얘기하더군요.” 아이콘은 클라에 있거든요. 쿠라 개발자에게 말해주세요”
아니, 도대체 왜 사람이 계속 바뀌는 거지? 무엇보다도, 어떤 요소가 서버에 있는지, 클래에 있는지, 비전공자가 어떻게 알 수 있는지? 그리고 이미지는 도대체 어떻게 관리하는 거지?윈도우를 보자. 데스크탑에 이미지가 있다. 이 사진의 이름은 myimage.png이다. 이 상황에서 전혀 다른 이미지를 다운로드한다. 그리고 같은 바탕화면에 놓는다. 이름을 「myimage.png」로 바꾸면, 바뀔까? 변하지 않는다 이미 그 위치에 존재하는 이름이기 때문이다 이미지 상에서 마우스 오른쪽 버튼을 누르면 ‘프로퍼티’라는 메뉴가 있다. 속성’ 을 누르면 이미지 정보가 나타난다.
그 정보에는 「위치」가 있다.User/young/Desktop/myimage.png 이런 모습이다. 위치는 고유해야 한다. 왜 그럴까? 운영체제가 그 고유의 위치를 통해 이미지를 인식하기 때문이다. 이제 우리는 이미지 파일에는 모두 위치가 있음을 알고 있다. 지금부터 이 위치를 ‘주소’라고 표현해 보자.
컴퓨터라면 모두 이미지 파일을 저장할 수 있다. 즉, 클라에도 이미지 파일이 있을 수 있고 서버에도 이미지 파일이 있을 수 있다. 그들은 모두 주소를 갖고 있다는 사실을 알고 있다. 그러면 당연히 서버에서 이미지를 공유하고, 클라가 이미지의 주소를 알고 있으면 서버에 있는 이미지를 클라에서 불러낼 수 있다. 클라에서 서버에 있는 이미지를 읽는다는 것은 네트워크를 통해 이미지 파일을 다운받는다는 것을 의미한다.
이미지 파일의 크기는 어느 정도인가? 작은 이미지도 있지만, 하나는 100MB를 넘는 큰 이미지도 있다. 그런 이미지를 내려받으려면 엄청난 시간이 걸린다. 고객은 기다려야 한다. 인터넷이 느린 곳이면 더 심할 거야 쿠라에게 이미지를 주면 더 장점이 있어 이미지를 다운로드하지 않아도 된다. 클라이언트 프로그램이 이미지 주소를 통해서 이미지를 취득한다. 네트워크보다 훨씬 빠르다.
그럼 서버에 있는 이미지를 왜 읽지? 그냥 꾸라에 이미지 두고 쓰면 안 되나? 쿠라의 이미지는 어떻게 바꿀까. 클래의 이미지를 바꾸려면 앱을 업데이트 할 필요가 있어. 버전 1.0.0에서 이미지 1을 보여줬다고 가정해 보자. 만약 버전이 1.0.1로 상승하여 ‘이미지 2’를 표시하게 되면 고객이 업데이트하여 앱의 버전을 올려야 한다. 만약 업데이트를 하지 않고 버전 1.0.0을 사용하는 고객이라면 「이미지 2」는 보이지 않는다.그럼 어떻게 해야 할까.상황에 따라 둘 다 사용해야 한다.최대한 네트워크에 부담을 주지 않도록 많은 이미지를 크랙에 둘 필요가 있지만 이미지가 바뀌었을 때 서비스에 영향을 준다면 서버부터 빼내야 한다. 즉, 클래스에 둘지 서버에 둘지를 결정하기 위해서는 이미지의 성격을 봐야 한다.조금 다른 이미지도 생각해보자 이미지를 만드는 주체는 「회사」에서도 「고객」일 수 있다. 인스타그램에는 많은 고객이 매일 많은 이미지를 업로드한다. 일반적인 다른 서비스에서도 고객은 자신의 프로필 사진을 업로드 한다. 이런 이미지는 고객이 만들어낸다. 즉 누가 어떤 이미지를 만들었는지 관계가 생긴다. 서로 관계가 맺어진 데이터는 단 0.000001%의 오류도 허용하지 않는 완전성의 문제가 있다. 누군가가 올린 프로필 사진이 다른 사람의 프로필에 보여서는 안 되게. 누군가 비공개로 올린 사진이 공개되지 않도록. 관리가 필요하다.
이런 이미지를 어떻게 관리할까? 화상은 모두 「주소」를 가지고 있다. 여기서의 주소는 「텍스트」이다.관계가 있는 텍스트는 관리가 어렵다. 그래서 DB에 넣어둘게. 이제는 이미지를 철저히 관리할 수 있다.
정리해보자.이미지 파일은 클라이나 서버 중 어느 하나의 컴퓨터에 있다. 그리고 각 컴퓨터는 이미지 주소를 통해 이미지에 접속한다. 이러한 화상을 변경하기 위해서는, 파일을 변경하는지 다른 주소를 지정하는 것이다. 그리고, 또 하나 있다. ‘프로필 화상’과 같은 파일의 경우 ‘관계’가 있기 때문에 관리가 필요하다. 그래서 ‘주소’를 DB에 넣어서 관리한다.
마지막으로 이미지가 클래스에 있는지 서버에 있는지를 확인하는 가장 좋은 방법은 API 문서를 보는 것이다. API를 통해 이미지의 주소(URL)를 서버로부터 받아왔다면 그 이미지는 서버에 있는 이미지라고 판단할 수 있다.
8장: 프레임워크나 라이브러리 iOS 앱을 만든다고 생각해보자. 이때 개발자는 버튼부터 하나하나 코딩하지 않는다. 버튼은 이미 애플이 만들어 놨다. 그렇게 해놓은 코드를 개발자가 사용한다. 그럼, 애플은 왜 프레임워크를 만들어 놓았을까? 애플은 앱스토어에 좋은 앱이 올라오길 바란다. 좋은 어플이 많으면 이 어플을 사용하기 위해서 아이폰을 사니까. 그런데 만약 애플 앱을 만드는데 버튼 하나하나를 코딩해서 너무 오랜 시간이 걸리면 어떨까? 이처럼 수많은 앱이 만들어지지는 않았을 것이다. 앱스토어에 있는 많은 앱은 애플이 제공하는 프레임워크 덕분이다.
애플은 이 프레임워크 사용법을 웹페이지에서 제공하고 있다. iOS 개발자에게는 「사전」과 같은 페이지이다. AppKit는 맥 OS에 올라가는 어플리케이션을 개발하기 위한 프레임워크, UIkit는 iOS 혹은 tvOS에 올라가는 어플리케이션을 개발하기 위한 프레임워크이다. 애플은 기기가 많기 때문에 기기마다 프레임워크가 존재한다. 애플에서는 이 프레임워크를 통칭해 코코아 프레임워크라고 부른다. 이처럼 대형 IT업체들은 개발자들이 자체 앱을 쉽고 빠르게 개발할 수 있도록 프레임워크를 만들어 제공하고 있다.

그러나 문제는 웹이다. 웹은 특정 회사의 소유가 아니다. 우리 모두의 것이다 그러면 웹 프레임워크 및 라이브러리는 누가 만들까? 많은 사람이 만든다. 이미 항간에는 수많은 프레임워크나 라이브러리가 있다. 그 중에서 ‘웹 프론트 엔드 프레임워크 및 라이브러리 3대 장’이라 불리는 가장 유명한 3가지가 있다. 그것은 Angular.js, React.js, Vue.js다. Angular.js는 구글에서 운영하고 있다. React.js는 페이스북으로 만들었다. Vue.js는 중국인이 만든 것이다. 이처럼 웹 프레임워크나 라이브러리는 페이스북이나 구글 같은 회사가 만들거나 개인이 만든다.
웹과 마찬가지로 서버도 특정 회사 소유가 아니기 때문에 다양한 프레임워크가 존재한다. 그리고 각 언어별로 유명한 프레임워크가 하나씩 있다. 자바는 스프링이라는 프레임워크가 유명하다. 자바와 스프링이라는 프레임워크를 사용하면 서버를 쉽고 빠르게 개발할 수 있다. 파이손은 장고(Django)라는 프레임워크가 유명하고 루비에게는 레일즈(Rails)라는 프레임워크가 있다. JavaScript에서도 서버를 개발할 수 있으며 이때는 익스프레스(Express.js)라는 프레임워크를 많이 사용한다.
그럼 라이브러리는 뭐지? 라이브러리도 다른 사람이 만들어 놓은 코드를 이용한다는 측면에서 프레임워크와 같다. 단, 프레임워크가 보다 큰 개념이다. 각종 라이브러리와 코드가 모여 프레임워크를 이룬다. 게다가 하나의 프로젝트에서 프레임워크는 하나만 사용할 수 있다. 하나의 자동차를 운전하면서 동시에 다른 자동차를 운전할 수 없는 것과 같다. 반면 라이브러리는 더 작은 개념이다. 망치나 가위 같은 도구이므로 한 프로젝트에 함께 사용할 수 있다.
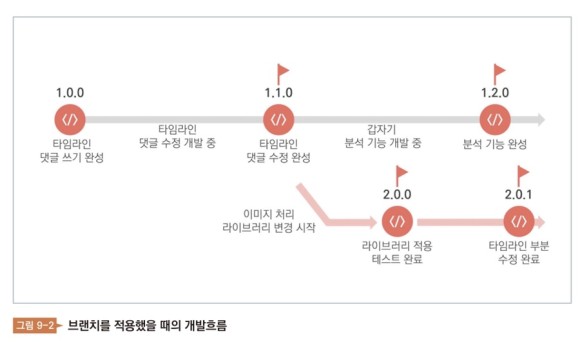
제9장 협업, 소스 관리, 디자인 커밋? 멀어? 개발자가 타임라인의 글을 완성해. 버전은 1.0.0으로 했다. 그런 다음 우선 순위인 타임라인 수정 기능을 즉시 개발하기 시작했다.완성 후의 버전은 1.1.0으로 끌어올렸다. 그런데 갑자기 기획팀에서 분석 기능이 필요하게 됐다고 한다. 곧바로 분석 기능을 개발하기 시작한다. 분석 기능을 완성 후의 버전은 1.2.0으로 했다. 그런데 갑자기 기획팀에서 분석 기능이 없어졌다고 한다. 개발자는 현재 버전인 1.2.0 상태의 코드에서 1.0.0 상태의 코드로 되돌려야 한다. 만약 분석 코드 1,000 행을 100개의 파일에 나누어 넣어둔다면? 끔찍하다
분석코드는 그대로 두면 안 되는가? 키트(Git)는 이런 문제를 해결해 준다. 날개를 통해 개발자는 개발 단계별로 ‘깃발’을 들 수 있다. 그 행위를 커밋(commit)이라고 한다. 커밋에게는 항상 메모가 따라다닌다. 어떤 개발을 했는지 적어주는 메모다. 그 메모를 「커밋 로그」라고 한다.
앞의 사례에서 개발자가 타임라인 수정을 완성하면 이번에는 커밋한다. 커밋 로그에는 「타임 라인 수정 완료」라고 적는다. 그러면 깃발은 거기에 깃발을 세운다. 깃발은 깃발과 깃발 사이의 변화와 누가 언제 관여하고 있으며, 어느 부분을 바꿨는지를 모두 추적해 준다. 또 체크아웃할 때 깃발이 꽂힌 부분의 코드로 이동할 수도 있다. 이것이 날개의 주된 기능인 「소스 코드의 버전 관리」다.
그 밖에 옷깃에는 여러 가지 기능이 있다. 블랑쉬는 분기 가지라는 뜻으로 새로운 가지를 뻗는 것을 말한다. 개발 중에 새로운 방향의 개발을 추가할 필요가 있을 때 개발자는 기존 개발에 계속 작업하는 것이 아니라 새로 가지를 치고 작업을 할 수 있다. 이렇게 하면 기존 브랜치에 커밋하는 것이 새로운 브랜치에 영향을 주지 않고 마찬가지로 새로운 브랜치에 영향을 주지 않는다. 이것에 의해, 하나의 프로젝트를 진행할 때, 동시에 복수의 기능을 충돌 없게 작업할 수 있게 된다. 그런 다음 각 브랜치에서 작업한 코드만 맞출 뿐이다.
코드를 맞추는 기능이 Merge이다. 옷깃은 단정하기 때문에 작업 부분이 겹치지 않으면 자연스럽게 맞춘다.만약 겹치는 부분이 있다면 옷깃은 ‘충돌(conflict)’을 가르쳐 어느 부분이 충돌했는지를 보여준다. 개발자는 그 부분만 수정하면 된다.
마지막으로 원격 저장소를 살펴보자. 여러 개발자가 각각 자신의 컴퓨터에 코드를 입력한다. 그럼 각 개발자의 컴퓨터에는 다른 코드가 존재한다. 다른 개발자가 작업한 코드를 맞추면 다른 게 된다. 이에 따라 개발자들은 날개를 기반으로 한 날개허브, 비트버킷 등 원격 저장소라는 것을 만들었다. 개발자가 자신의 컴퓨터(로컬)로 작업한 뒤 커밋하면 그 결과를 원격 저장소로 보낼 수 있고, 원격 저장소로 이미 작업한 결과를 가져올 수도 있다. 구글 드라이브에서 자료를 공유하도록 파일을 다운받을 수도 있고, 새로 작업한 파일을 올릴 수도 있다.
디자이너와 개발자 디자이너는 주로 포토샵과 일러스트를 사용해 작업한다. 그러나 이 두 프로그램은 앱이나 웹 디자인에 최적화된 프로그램은 아니다. 따라서 포토샵과 일러스트로 작업하면 개발자가 요소의 넓이, 높이, X축에서 얼마나 떨어져 있는지 등의 수치를 하나씩 파악해야 하는 불편이 생긴다. 그래서 개발자들은 가이드를 찾기 시작한다. 요소 위에 요소가 있는 경우, 그림자가 지는 경우 등 각각의 사안에 대해 개발자가 이를 어떻게 처리해야 하는지 일일이 설명하기는 쉽지 않다. 또 가이드를 어느 정도까지 상세히 줘야 하는지도 모호하다.
이처럼 디자이너와 개발자 간의 협업을 위해 스케치, 재플린, 피그마, XD 등의 프로그램이 등장했다. 디자이너의 작업결과물 수치를 보여주는 것으로 따로 디자이너가 가이드를 쓸 필요가 없다.
또한 스마트폰은 기종마다 가로 세로 ‘비율’이 다르다. 이 비율 때문에 디자인 구현에서 엄청난 차이가 나타난다. 보통 디자이너는 한 기기를 기준으로 결과를 준다. 혹은 iOS/Android 각각 하나의 기기를 기준으로 결과를 부여한다. 수백 개가 넘는 기기의 디자인을 모두 맞출 수는 없다. 따라서 디자이너는 가이드에게 관심을 가져야 한다. 개발 코드까지는 아니더라도 각 프레임워크에서 제공하는 가이드 문서를 어느 정도 숙지하고 있어야 한다. 애플은 HIG(Human Interface Guideline)를 제공하여 애플의 기기가 어떤 방침을 가지고 있는지를 기술하고 있다. 구글은 Material Design이라는 가이드를 제공한다.
부록. API 문서로 서비스 분석하기
그 밖에 옷깃에는 여러 가지 기능이 있다. 블랑쉬는 분기 가지라는 뜻으로 새로운 가지를 뻗는 것을 말한다. 개발 중에 새로운 방향의 개발을 추가할 필요가 있을 때 개발자는 기존 개발에 계속 작업하는 것이 아니라 새로 가지를 치고 작업을 할 수 있다. 이렇게 하면 기존 브랜치에 커밋하는 것이 새로운 브랜치에 영향을 주지 않고 마찬가지로 새로운 브랜치에 영향을 주지 않는다. 이것에 의해, 하나의 프로젝트를 진행할 때, 동시에 복수의 기능을 충돌 없게 작업할 수 있게 된다. 그런 다음 각 브랜치에서 작업한 코드만 맞출 뿐이다.
코드를 맞추는 기능이 Merge이다. 옷깃은 단정하기 때문에 작업 부분이 겹치지 않으면 자연스럽게 맞춘다.만약 겹치는 부분이 있다면 옷깃은 ‘충돌(conflict)’을 가르쳐 어느 부분이 충돌했는지를 보여준다. 개발자는 그 부분만 수정하면 된다.
마지막으로 원격 저장소를 살펴보자. 여러 개발자가 각각 자신의 컴퓨터에 코드를 입력한다. 그럼 각 개발자의 컴퓨터에는 다른 코드가 존재한다. 다른 개발자가 작업한 코드를 맞추면 다른 게 된다. 이에 따라 개발자들은 날개를 기반으로 한 날개허브, 비트버킷 등 원격 저장소라는 것을 만들었다. 개발자가 자신의 컴퓨터(로컬)로 작업한 뒤 커밋하면 그 결과를 원격 저장소로 보낼 수 있고, 원격 저장소로 이미 작업한 결과를 가져올 수도 있다. 구글 드라이브에서 자료를 공유하도록 파일을 다운받을 수도 있고, 새로 작업한 파일을 올릴 수도 있다.
디자이너와 개발자 디자이너는 주로 포토샵과 일러스트를 사용해 작업한다. 그러나 이 두 프로그램은 앱이나 웹 디자인에 최적화된 프로그램은 아니다. 따라서 포토샵과 일러스트로 작업하면 개발자가 요소의 넓이, 높이, X축에서 얼마나 떨어져 있는지 등의 수치를 하나씩 파악해야 하는 불편이 생긴다. 그래서 개발자들은 가이드를 찾기 시작한다. 요소 위에 요소가 있는 경우, 그림자가 지는 경우 등 각각의 사안에 대해 개발자가 이를 어떻게 처리해야 하는지 일일이 설명하기는 쉽지 않다. 또 가이드를 어느 정도까지 상세히 줘야 하는지도 모호하다.
이처럼 디자이너와 개발자 간의 협업을 위해 스케치, 재플린, 피그마, XD 등의 프로그램이 등장했다. 디자이너의 작업결과물 수치를 보여주는 것으로 따로 디자이너가 가이드를 쓸 필요가 없다.
또한 스마트폰은 기종마다 가로 세로 ‘비율’이 다르다. 이 비율 때문에 디자인 구현에서 엄청난 차이가 나타난다. 보통 디자이너는 한 기기를 기준으로 결과를 준다. 혹은 iOS/Android 각각 하나의 기기를 기준으로 결과를 부여한다. 수백 개가 넘는 기기의 디자인을 모두 맞출 수는 없다. 따라서 디자이너는 가이드에게 관심을 가져야 한다. 개발 코드까지는 아니더라도 각 프레임워크에서 제공하는 가이드 문서를 어느 정도 숙지하고 있어야 한다. 애플은 HIG(Human Interface Guideline)를 제공하여 애플의 기기가 어떤 방침을 가지고 있는지를 기술하고 있다. 구글은 Material Design이라는 가이드를 제공한다.
부록. API 문서로 서비스 분석하기
앱이든 웹이든 모두 텍스트와 이미지로 구성돼 있다. API 분석의 첫 단계는 텍스트와 이미지의 출처를 구분하는 것이다.
- 해당 텍스트는 클라이언트에 있는가? 서버에서 가져왔나?2. 해당 이미지는 클라이언트에 있는가? 서버에서 가져왔어?
- API 문서 안에는 GET 요청만 있는 것이 아니다. POST, PUT, PATCH, DELETE 요청도 있다. 그러나 주의 깊게 봐야 할 정보는 GET이다. 어떤 정보를 읽고 있는지 확인하려면 GET 요청을 봐야 한다. 물론 사정에 따라서는, GET가 아닌 POST로 정보를 읽기도 한다. API는 개발자 간의 약속이기 때문에 회사나 기술 사정에 따라 바꿔 사용할 수 있다. 따라서 API 문서의 설명을 꼭 읽어보라.